Syntax der zeilenorientierten Suchanfragesprache
Übersicht
- 1. Allgemeines zur Suchanfrage
- 1.1. Suchbegriff und Suchmuster
- 1.2. Zeichensatz und Sonderzeichen
- 1.3. Groß-/Kleinschreibung
- 1.4. Klammerungen
- 1.5. Suchanfrage und Suchergebnis
- 1.6. Suchlauf und temporäre Wortformenlisten
- 2. Suchoperatoren
- 2.1. Wortformoperatoren
- 2.1.1. Die
Platzhalteroperatoren
*,?,+ - 2.1.2. Der
Grundformoperator
& - 2.1.3. Der
Ignorierungsoperator
$ - 2.1.4. reguläre Ausdrücke
mit
#REG()
- 2.2. Logische Operatoren
- 2.3. Abstandsoperatoren
- 2.3.1. Der
Wortabstandsoperator
w - 2.3.2. Der
Satzabstandsoperator
s - 2.3.3. Der
Absatzabstandsoperator
p
- 2.4. Annotationsoperatoren
- 2.4.1. Der
Operator
MORPH
- 2.5. Kombinationsoperatoren
- 2.5.1. Der
Operator
IN - 2.5.2. Der
Operator
OV
- 2.6. Elementoperatoren
- 2.6.1. Der
Operator
ELEM
- 2.7. Textbereich-Operatoren
- 2.7.1. Der
Operator
LINKS - 2.7.2. Der
Operator
RECHTS - 2.7.3. Der
Operator
INKLUSIVE - 2.7.4. Der
Operator
EXKLUSIVE - 2.7.5. Der
Operator
BED
- 3. diverse Textauszeichnungen
- 3.1 Textpositionen
- 4. Generelles zu
- 4.1 regulären Ausdrücken
- 4.2 Sonderzeichen in Suchanfragen
- 4.3 interne Begrenzung von Wortformen
- 4.2 Sonderzeichen in Suchanfragen
- Der vorliegende Text wurde in Grundzügen der COSMAS I-Referenz entnommen, neu strukturiert, aktualisiert und erweitert.
- Eine Sammlung von einfachen linguistischen Problemstellungen und Lösungen finden Sie im Kochbuch.
1. Allgemeines zur Suchanfrage
Mit der Suchanfragesprache von COSMAS II
lassen sich linguistische und andere sprachbezogene Fragestellungen
umsetzen.
Neben der Suche nach einfachen Wortformen bietet
COSMAS II eine
Vielzahl von Möglichkeiten für Kombinationssuchen und Suchen
mit Suchmustern.
Was Sie für die Eingabe von Suchanfragen wissen sollten:
- Suchbegriffe und Suchmuster
- Zeichen und Sonderzeichen
- Groß-/Kleinschreibung
- Klammerungen
- Suchanfrage und Suchergebnis
- Suchlauf und temporäre Wortformenlisten
Die Suchanfragesyntax gewährleistet eine relativ hohe Treffergenauigkeit. Unter Suchanfragesyntax ist die Verbindung von bestimmten Einheiten (Suchoperatoren) zu einer Suchanfrage nach den Regeln der Abfragesprache zu verstehen.
1.1. Suchbegriff und Suchmuster
Unter Suchbegriff ist im Zusammenhang mit COSMAS II folgendes zu verstehen:
- in der Suchanfrage:
- Wort im lexikalischen bzw. grammatischen Sinn
- Satzzeichen oder anderes Sonderzeichen
- Zahl
- Suchmuster:
- Wort bzw. Wortsegment mit den
Platzhalteroperatoren
*,?und+ - Grundform (ein unflektiertes Wort bzw. ein
Wortbildungsmorphem) mit dem
Grundformoperator
& - Wort mit dem
Ignorierungsoperator
$in Bezug auf Groß-/Kleinschreibung
- Wort bzw. Wortsegment mit den
Platzhalteroperatoren
- in Korpustexten:
- in den Texten des aktiven Korpus durch die Suchanfrage gefundene Wortform(en) bzw. gefundene(s) Satz- oder andere(s) Zeichen (auch Zahlen)
Logische Operatoren als Suchbegriffe
Sollen die Wörter "und", "oder", "nicht", "and", "or", "not" Suchbegriffe sein, sind sie in Anführungsstriche zu setzen.
Beispiel-Suchanfragen:
bevor /+w5 "nicht"groß "oder" kleinKind "und" Kegel
|
- Ohne Anführungsstriche werden die oben genannten Wörter als logische Operatoren behandelt.
Platzhalteroperatoren als Suchbegriffe
Sollen die Platzhalter ?, * oder
+
Suchbegriffe oder Teile von Suchbegriffen sein, ist jeweils ein "\"
voranzustellen.
Beispiel-Suchanfragen:
\?\*\+
|
- Ohne vorangestellten Backslash ("\") werden die oben genannten Zeichen als Platzhalteoperatoren behandelt.
\\ |
Soll der Backslash ("\") selbst Suchbegriff oder Teil eines Suchbegriffs sein, muss ebenfalls ein Backslash vorangestellt werden.
Suchen nach dem Sonderzeichen &
Das & nimmt bei der internen Kodierung von Korpora eine besondere Stellung ein, weil es neben der typografischen Darstellung des Ampersands im Text (Bsp.: Kind&Kegel) auch die Funktion innehat, Sonderzeichen und Zeichen aus anderen Sprachen als Zeichenentität zu kodieren, z.B. als „ für „ und “ für “ oder → für den →. Außerdem gibt es verschiedene Kodierungsarten wie a) interne Schreibweise mit Zeichenentität (&), b) interne hexadezimale Schreibweise (&) und c) interne dezimale Schreiweise (&).
Zur Vereinfachung und -einheitlichung kann das & in COSMAS II direkt als '&' gesucht werden, sowohl als einzelnes Zeichen als auch innerhalb eines Wortes. Außerdem kann es auch über seine interne Repräsentation (siehe: a - c) abgefragt werden. Alle Suchvarianten ergeben die selben Treffer.
Kinder /+w1 & /+w1 KegelFirma Kraut&Rüben
|
1.2. Zeichensatz und Sonderzeichen
COSMAS II akzeptiert die deutschen Sonderzeichen (ä, Ä, ö, Ö, ü, Ü sowie ß) in den Wörtern der Suchanfrage sowie alle weiteren Sonderzeichen von ISO 8859-1, dem Zeichensatz der westeuropäischen Sprachen.
![[ISO-Latin1.jpg]](/cosmas2/win-app/hilfe/suchanfrage/eingabe-grafisch/syntax/ISO-Latin1.jpg) (Grafik entnommen aus Wikipedia) |
- Ausnahme: Bei der Verwendung des Grundformoperators & muss in der Grundform das "ß"-Zeichen durch "ss" ersetzt werden, z.B. "&gross".
Das Et-Zeichen &
Eine Ausnahme innerhalb ISOlat1 bildet das Et-Zeichen '&', das wegen seiner Funktion in HTML- und UNICODE-Zeichenkodierungen als & kodiert ist und als solches gesucht werden muss.
| H&M-Kette |
Diese Suchanfrage findet Vorkommnisse von H&M-Kette.
Wird das & als freistehendes Zeichen und nicht als Bestandteil eines Wortes gesucht, muss es zwischen " und " geschrieben werden:
| Bang "&" Olufsen |
Sonderzeichen am Wortende
Jede Wortform, die in den Korpustexten mit einem Sonderzeichen endet, ist nur ohne dieses Zeichen suchbar. Davon ausgenommen sind Abkürzungen, sie behalten ihren Punkt auch in der Suchanfrage.
Wenn z.B. nach "usw." oder "Prof." gesucht werden soll, muss in der Suchanfrage stehen:
Beispiel-Suchanfragen:
usw.Prof.
|
Suche nach Wortformen mit Sonderzeichen außerhalb von ISOLat1
COSMAS II nutzt als Standard-Zeichensatz ISOLat1 (entspricht ISO8859-1). Zeichen, die sich nicht in diesem Zeichensatz befinden bzw. Zeichen, von denen man nicht genau weiss, wie man sie über die Tastatur eingeben soll, können als XML-Zeichen mit dezimalem UNICODE-Wert eingegeben werden.
Beispiel: Auslassungspunkte
| Zeichen | Symbol | HTML-Zeichen | UNICODE-Wert dezimal |
UNICODE-Wert hexadezimal |
|---|---|---|---|---|
| Auslassungspunkte | … | … | 8230 | x2026 |
Beispiel: Suchanfrage nach dem Sonderzeichen allein
"…"
|
Bemerkung: da das &-Zeichen am Anfang des Suchbegriffs steht, muss der gesamte Suchbegriff zwischen Anführungszeichen geschrieben werden, damit COSMAS II es vom Lemmatisierungsoperator unterscheiden kann.
Beispiel: Suchanfrage nach dem Sonderzeichen innerhalb eines Suchbegriffs
"*…" "*…*" "…*"
|
Wie lautet die Kodierung meines Sonderzeichens
Der Dezimalwert vieler Sonderzeichen läßt sich z.B. in Wikipedia nachschlagen. Siehe zum Beispiel den Wikipedia-Eintrag für die Auslassungspunkte.
Wortliste
Der WORT-Operator verfügt außerdem über eine
globale Wortformliste, die
Sie aufrufen können, um sich die Wortformen im momentan aktiven
Archiv präsentieren zu lassen und gegebenenfalls eine davon
auszuwählen.
1.3. Groß-/Kleinschreibung
Globale Einstellungen (= Suchmodalitäten)
Ob die Groß-/Kleinschreibung in einer Suchanfrage beachtet oder ignoriert werden, hängt in erster Linie davon ab, welche allgemeinen Einstellungen Sie in den Optionen zur Suche getroffen haben. Dort können Sie angeben, ob die Groß-/Kleinschreibung nur am Wortanfang, für den Rest des Wortes oder das ganze Wort beachtet werden soll.Beispiel
sein
|
Falls die Optionen zur Groß-Kleinschreibung deaktiviert sind, liefert
diese Suchanfrage Treffer für "sein", "Sein" oder "SEIN".
Bei Aktivierung der Groß-/Kleinschreibung am Wortanfang dagegen erhalten
Sie nur Treffer für "sein".
Beispiel
Sein
|
Falls die Optionen zur Groß-Kleinschreibung deaktiviert sind, liefert
diese Suchanfrage dieselben Treffer wie die vorhergehende
Suchanfrage sein.
Bei Aktivierung der Groß-/Kleinschreibung am Wortanfang dagegen erhalten
Sie ausschließlich Treffer für "Sein".
Ignorierungsoperator für die wortweise Wahl der Groß-/Kleinschreibung
Zusätzlich zu den globalen Suchmodalitäten (Groß-/Kleinschreiboptionen) können Sie für jeden Suchbegriff in Ihrer Suchanfrage festlegen, ob die vorgegebene Groß-/Kleinschreibung ignoriert werden soll.Weitere Beispiele
- Weitere Beispiele zur Suche abhängig von Groß-/Kleinschreibung
Erweiterte Optionen für die wortweise Wahl der Groß-/Kleinschreibung
Eine Erweiterung des Ignorierungsoperators bilden die ebenfalls als Präfix formulierten erweiterten Groß-/Kleinschreibungsoptionen, die zusätzlich auch die Berücksichtigung der diakritischen Zeichen steuern. Diese erweiterten Optionen gelten für Suchbegriffe, nicht aber für Grundformen oder reguläre Ausdrücke.
Beispiel
:EiDb:Würde
|
Bei der Suche nach diesem Suchbegriff wird die Groß-/Kleinschreibung des ersten Buchstabens ignoriert (Ei), die diakritischen Zeichen dagegen werden beachtet (Db).
Die erweiterten Optionen werden zwischen zwei ':' geschrieben. Zwischen ihnen und dem Suchbegriff darf kein Leerzeichen stehen; der zweite ':' dient als Trenner.
Liste der erweiterten Optionen
| anwendbar auf | Option | Beschreibung | |
| A | alle Zeichen | :Ab :Ai |
Groß-/Kleinschreibung &
diakritische Zeichen beachten Groß-/Kleinschreibung & diakritische Zeichen ignorieren |
| E | erstes Zeichen | :Eb :Ei :Eg :Ek |
Groß-/Kleinschreibung beachten Groß-/Kleinschreibung ignorieren Großschreibung erzwingen Kleinschreibung erzwingen |
| R | restliche Zeichen | :Rb :Ri :Rg :Rk |
Groß-/Kleinschreibung beachten Groß-/Kleinschreibung ignorieren Großschreibung erzwingen Kleinschreibung erzwingen |
| D | alle Zeichen | :Db :Di |
diakritische Zeichen beachten diakritische Zeichen ignorieren |
Wie dem obigen Beispiel entnommen werden kann, können alle 4 Optionen miteinander kombiniert werden. Zwischen den einzelnen Optionen sollte kein ':' verwendet werden.
1.4. Klammerungen
Enthält Ihre Suchanfrage mehr als einen Abstandsoperator, sind runde Klammern zu setzen.
Beispiel-Suchanfragen:
(Tag /+w2 offenen) /+w1 Tür
|
Auch möglich, aber zeitaufwändiger, weil der ein sehr häufiges Wort ist:
((Tag /+w1 der) /+w1 offenen) /+w1 Tür
|
Enthält Ihre Suchanfrage logische Operatoren und Abstandsoperatoren, sind ebenfalls runde Klammern zu setzen.
Beispiel-Suchanfragen:
&herausfordern oder (&fordern /+s0 heraus)(Landschaft oder Gegend) /s0 &schauen((schöne oder große) /+w3 Augen) /s0 &machen
|
1.5. Suchanfrage und Suchergebnis
Die Treffermenge kann aus Einzelworttreffern oder aus Mehrworttreffern bestehen, was von der Syntax der Suchanfrage abhängt.
Enthält Ihre Suchanfrage nur einen Suchbegriff oder sind mehrere Suchbegriffe mit logischen Operatoren verknüpft, besteht die Treffermenge aus Einzelworttreffern.
Beispiel-Suchanfragen:
Willkommenanscheinend oder scheinbar
|
- Bei der Verwendung des logischen
UND-Operators ist in den Korpustexten oft nur einer von beiden Suchbegriffen sichtbar, weil sich der zweite außerhalb des angezeigten Kontextes befindet.
Haben Sie in Ihrer Suchanfrage
Abstandsoperatoren verwendet,
besteht die Treffermenge aus Gruppen von zusammengehörenden
Suchbegriffen.
Die nachfolgende Suchanfrage
erzeugt beispielsweise Gruppen von zwei Treffern innerhalb eines Satzes
bestehend aus den beiden Suchbegriffen.
Beispiel-Suchanfrage:
offen /s0 sprechen
|
Im Zusammenhang mit der Ergebnispräsentation und -sortierung behandelt COSMAS II die zusammengehörenden Suchbegriffe der Gruppen immer als Mehrworttreffer.
1.6. Suchlauf und temporäre Wortformlisten
Bei Anwendung der Wortformoperatoren
*, ?,
+, &
und $ ist der Suchlauf
in drei Phasen unterteilt:
- 1. Phase: Korpusvalidierung der Treffer
- COSMAS II ermittelt im aktiven Korpus zunächst die zu jedem einzelnen Suchmuster der Suchanfrage passenden Wortformen. Hierbei werden automatisch sogenannte temporäre Wortformlisten erstellt.
- 2. Phase: Editieren der temporären Wortformlisten
- In jeder temporären Wortformliste, die Sie sortieren lassen können, wählen Sie die Wortformen aus, die Sie in der 3. Phase in den Texten suchen lassen möchten.
- 3. Phase: Belegsuche
- COSMAS II sucht die Belegstellen zu den angewählten Wortformen der temporären Wortformliste.
Ob in der 1. Phase des Suchlaufs temporäre Wortformlisten angezeigt werden oder nicht, ergibt sich aus der von Ihnen vorgenommenen Einstellung der Optionen zur Suche.
- Für bestimmte Suchmuster mit
dem Platzhalteroperator
*bzw. dem Grundformoperator&gibt es sehr viele passende Wortformen in den Korpustexten (z.B. für das Suchmuster *en).
In diesem Zusammenhang kann es passieren, dass eine temporäre Wortformliste nicht vollständig ist. Auf dem Bildschirm erscheint eine entsprechende Meldung.
2. Suchoperatoren
Übersicht
COSMAS II kennt folgende Klassen von Suchoperatoren:
- Wortformoperatoren
- die Platzhalteroperatoren
*,?,+ - den Grundformoperator
& - den Ignorierungsoperator
$ - den Operator
#REG()für reguläre Ausdrücke
- die Platzhalteroperatoren
- Logische Operatoren
- die Operatoren
UND,ODER,NICHT
- die Operatoren
- Abstandsoperatoren
- den Wortabstandsoperator
w - den Satzabstandsoperator
s - den Absatzabstandsoperator
p
- den Wortabstandsoperator
- Annotationsoperatoren
- den Operator
MORPH
- den Operator
- Kombinationsoperatoren
- Elementoperatoren für SGML- bzw. XML-Annotationen
- den Operator
#ELEM
- den Operator
- Textbereich-Operatoren
2.1. Wortformoperatoren
Wortformoperatoren sind Funktionszeichen für spezielle Suchoperationen zur Ermittlung bestimmter im aktiven Korpus vorkommender Wortformen. Zusammen mit Wörtern bzw. Wortsegmenten bilden sie Suchmuster, zu denen COSMAS II die im aktiven Korpus vorkommenden passenden Wortformen ermittelt.
COSMAS II kann nach mehreren Suchbegriffen gleichzeitig suchen. Die einzelnen Suchbegriffe müssen in der Suchanfrage durch logische Operatoren und/oder Abstandsoperatoren miteinander verknüpft sein.
Zu den Wortformoperatoren gehören
- die Platzhalteroperatoren
*,?und+ - der Grundformoperator
& - der Ignorierungsoperator
$ - der Operator
#REGfür reguläre Ausdrücke
Darüber hinaus ist auch eine einfache Wortform oder ein Wortsegment ein Operator dieser Kategorie.
Beispiel
Eine simple Suchanfrage kann durch die Suche nach einer einfachen Wortform gestartet werden.
Willkommen
|
Groß-/Kleinschreibung
Die Beachtung der Groß-/Kleinschreibung und der diaktritischen Zeichen kann durch verschiedene, hier beschriebene Optionen gesteuert werden.
Suche nach Affixen (Suffixe und Präfixe)
Der Grundformoperator ermöglicht außerdem das Suchen nach Affixen.
Wortformlisten und Listenoptionen
Wortformoperatoren können zusätzlich mit Listenoptionen ergänzt werden und erzeugen Wortformlisten, die verwaltet werden können.
2.1.1. Die Platzhalteroperatoren *,
?, +
Diese Operatoren ermöglichen die Suche nach Wörtern und Wortsegmenten mit ergänzenden Zeichen(ketten). Das Wort (bzw. das Wortsegment) als solches ist ebenfalls gleichzeitig Suchbegriff.
Diese Operatoren sind "Platzhalter" für beliebige Zeichen:
*steht für 0 bis n Zeichen (keines bis "unendlich" viele),?steht für genau ein Zeichen,+steht für 0 oder 1 Zeichen (höchstens eines).
Diese Operatoren können am Anfang oder am Ende von Wörtern bzw. Wortsegmenten stehen bzw. von Wortsegmenten umgeben sein. Sie sind ohne Leerzeichen mit dem Wort bzw. Wortsegment in das Suchanfragefenster zu schreiben.
Operator(en) und Wort bzw. Wortsegment(e) bilden das Suchmuster.
Ein solches Suchmuster muss mindestens zwei Buchstaben enthalten. Wenigstens ein Buchstabe muss am Anfang oder am Ende des Suchmusters stehen.
Die Operatoren können mehrmals in einem Suchmuster vorkommen.
Beispiel-Suchanfragen
Bei Verwendung des Platzhalters *
(beliebig viele oder gar kein Zeichen)
Mond*
|
erhalten Sie in der temporären Wortformliste bspw. die Treffer
- "Mond": das Wort selbst, da der Platzhalter in diesem Fall für kein Zeichen steht,
- "Mondes": eine der Flexionsformen des Wortes oder
- "Mondschein": ein beliebig langes Kompositum mit dem vorgegebenen Wortanfang.
*mond |
Hier erhalten Sie - neben dem Wort "mond" selbst - u.a. die Treffer "Neumond", "Vollmond", aber auch "Raymond" oder "Hammond".
Bei Verwendung des Platzhalters ? (genau ein Zeichen)
Mond? |
enthält die Wortformliste Treffer für "Monde" - einerseits die Flexionsformen des deutschen Wortes "Mond", andererseits das gleichlautende französische Wort - oder auch "Mondo" oder "Mondy".
Bei Verwendung des Platzhalters + (höchstens ein Zeichen)
Mond+
|
erhalten Sie neben allen Treffern der obigen Suchanfrage
Mond? auch das Wort "Mond" selbst.
Ob Groß-/Kleinschreibung berücksichtigt wird, wenn das Suchmuster mit einem Wort bzw. Wortsegment beginnt, ergibt sich aus der von Ihnen vorgenommenen Einstellung in den Optionen zur Suche.
- Beispiele zur Suche nach orthografischen Varianten
Platzhalter als suchbare Zeichen
Damit die Platzhalter zu suchbaren Zeichen werden, d.h. um ihre Platzhalterfunktion zu
deaktiviert, muss man ein \ davor setzen.
Der Suchausdruck für z.B. Student*in muss somit wie folgt aussehen:
Student\*in |
Wortformlisten und Listenoptionen
- Wortformlisten können verwaltet werden.
- Die Erzeugung von Wortformlisten mit Platzhaltern kann zusätzlich mit Listenoptionen gesteuert werden.
- Lesen Sie hier mehr über die automatische Segmentierung von langen Wortformlisten.
2.1.2. Der Grundformoperator &
Der Grundformoperator - oder auch Lemmatisierungsoperator -
ermöglicht nicht nur
die Suche nach Flexions-, sondern auch nach Wortbildungsformen
zu einer in der Suchanfrage eingegebenen Grundform (einem
unflektierten Wort bzw. Wortbildungsmorphem).
Bei der Verwendung des Grundformoperators & muss in der
Grundform das ß-Zeichen durch ss
ersetzt werden, z.B. &gross.
Die Grundform als solche ist ebenfalls gleichzeitig ein Suchbegriff.
Im Zusammenhang mit COSMAS II sind Grundformen
- unflektierte Simplizia verschiedener Wortarten
- unflektierte Ableitungen und Komposita
- Wortbildungsmorpheme
Der Operator muss ohne Leerzeichen am Anfang der Grundform stehen.
Beispiele zur Anwendung des Grundformoperators
- Suche mit Flexionsformen
- Suche mit Komposita (Wortbildungsformen)
- Suche mit Ableitungen und Affixen (Wortbildungsformen)
Erweiterte Optionen für Komposita
Bei eingeschalteter Option für Komposita sind auch folgende erweiterte Komposita-Optionen verfügbar.
Option für die Groß-/Kleinschreibung
Mittels der Optionen &G& und &K&, die ebenfalls als erweiterte Optionen fungieren, läßt sich auf die Groß-/Kleinschreibung des ersten alphabetischen Zeichens einer Wortform Einfluss nehmen. Dies ist eine allgemeine Option, die für alle von dem angegebenen Lemma ableitbaren Wortformen gilt, nicht nur auf die Komposita. Sie bezieht sich außerdem auf die Schreibweise, wie sie im Text gefunden wird.
Beispiel
&G&fein &k&werden
|
Anmerkungen
Mit dem ersten alphabetischen Zeichen ist der erste Buchstabe eines Wortes gemeint, das auf mögliche Spezial- oder Satzzeichen am Wortanfang folgt. Anbei einige Beispiele dafür, welcher Buchstabe auf Groß-/Kleinschreibung geprüft wird:
| Textwort | geprüfter Buchstabe |
|---|---|
| "Trauer"-spiel | T |
| 0:1-Trauerspiel | T |
| 08/15-Trauerzeremonie | T |
Diese Option ist mit Vorsicht einzusetzen, da beispielsweise mit der Klein-Option Adjektive und Verben am Satzanfang nicht mehr gefunden werden.
Wortformlisten und Listenoptionen
- Wortformlisten können sitzungsübergreifend verwaltet werden.
- Die Erzeugung von Wortformlisten mit dem Grundformoperator kann zusätzlich mit Listenoptionen gesteuert werden.
- Lesen Sie hier mehr über die automatische Segmentierung von langen Wortformlisten.
2.1.3. Der Ignorierungsoperator $
Dieser Operator ermöglicht eine teilweise
groß-/kleinschreibungsunabhängige Suche.
Er ist nur von Bedeutung, wenn die Option
Groß-/Kleinschreibung beachten eingeschaltet ist
und folglich die in der Suchanfrage vorgegebene
Groß-/Kleinschreibung bei der Suche beachtet wird.
Trotz aktivierter Option Groß-/Kleinschreibung beachten haben Sie
die Möglichkeit, einen bestimmten Suchbegriff
einer Suchanfrage groß-/kleinschreibungsunabhängig suchen zu lassen:
Sie setzen den Ignorierungsoperator $ ohne
Leerzeichen an den Anfang des betreffenden Suchbegriffs. Dadurch
ist die oben erwähnte Option in Bezug auf
diesen Suchbegriff außer Kraft gesetzt.
Beispiel-Suchanfrage:
(Tag /+w2 $offenen) /+w1 Tür
|
Sofern in den Texten des aktiven Korpus vorhanden, erhalten Sie Belege z.B. für "Tag der offenen Tür", "Tag der Offenen Tür", "Tag der OFFENEN Tür".
"Tag" und "Tür" werden so gefunden, wie sie in der Suchanfrage stehen; es gibt also keine Treffer für z.B. "TAG", auch wenn diese Schreibweise innerhalb der Wortgruppe vorhanden sein sollte.
Ohne diesen Operator würde COSMAS II die Wortform "offenen" nur so finden, wie sie in der Suchanfrage steht, nämlich in klein geschriebener Form: "Tag der offenen Tür".
- Beispiele zur Suche abhängig von Groß-/Kleinschreibung
2.1.4. Reguläre Ausdrücke mit #REG()
Für die Formulierung von Suchbegriffen mittels erweiterten regulären Ausdrücken
kann der Operator #REG eingesetzt werden. Pro Suchanfrage sind mehrere davon
möglich. Die regulären Operatoren *, ? und
+ werden in COSMAS II zwar ebenfalls als Platzhalter-Operatoren eingesetzt;
innerhalb von #REG() werden sie jedoch nach einer anderen Syntax eingesetzt.
Inhalt
- Syntax
- Beispiele
- weiterführendes Beispiel
- Hinweis zu den Klammern
- Hinweis zu der Suche nach Umlauten, Zeichen mit Diakritika und dem ß
- Optionen
- Begrenzung und zusätzliche Listenoptionen
Syntax
Der Operator #REG() kann einen oder mehrere reguläre
Ausdrücke1 aufnehmen, z.B.
#REG(Ausdruck) oder #REG(Ausdr1 Ausdr2 etc.). Jeder Ausdruck
steht für eine Wortform und generiert eine eigene temporäre Wortformliste.
Die verschiedenen Ausdrücke werden intern durch ein logisches oder im Endergebnis
zusammengeführt.
Die Syntax der erweiterten regulären Ausdrücke ist zu umfangreich, als dass sie hier beschrieben werden könnte. Sie kann allerdings überall im Internet nachgelesen werden. Mit den zahlreichen nachfolgenden Beispielen können schon etliche interessante Fälle abgedeckt werden.
Folgende Einschränkungen seien allerdings an dieser Stelle erwähnt: vordefinierte Symbole
wie \< (Wortanfang), \> (Wortende), \w (Klasse
der alphanumerischen Zeichen) und /W (Klasse aller nicht-alphanumerischen
Zeichen) verhalten sich anders als erwartet und sollten eher vermieden werden.
Bemerkung
Beachten Sie bitte, welche Option einen Einfluss
auf die Ausführung von #REG() hat.
Beispiele
#REG(Archi.*ung)
|
Damit werden Wortformen gesucht, die Archi und ung enthalten. Abhängig von der eingestellten Option Groß-/Kleinschreibung beachten wird hierbei die Groß-/Kleinschreibung der Zeichen gegenüber dem regulären Ausdruck beachtet oder nicht. Die Teilbegriffe Archi bzw. ung werden nicht nur am Wortanfang und -ende gesucht, sondern auch innerhalb der Wortformen.
#REG( ^Archi.*ung$ )
|
Durch das Einfügen der Operatoren ^ (für Wortanfang) und $ (für Wortende) werden einzig die Wortformen gesucht, die mit Archi beginnen und mit ung enden.
#REG( Verschlusss?ache ) |
Hiermit werden Varianten von Verschlusssache mit 2 oder 3 's' gesucht.
#REG( Redakteur(s|e|en|in|innen)? ) |
Hiermit werden mit Hilfe der runden Klammern Varianten von Redakteur mit den fakultativen Endungen s, e, en, in und innen gesucht.
Siehe hierzu auch den Hinweis zu den runden Klammern weiter unten.
#REG( ^1[89][0-9][0-9]$ ) |
Damit lassen sich Jahreszahlen zwischen 1800 und 1999 suchen.
#REG( ^1[89][0-9]{2}$ ) |
Durch die Angabe von {2} lassen sich in etwas kompakterer Form die Jahreszahlen zwischen 1800 und 1999 suchen.
#REG( ^[0-9]{2}\.[0-9]{2}\.[0-9]{2,4}$ ) |
Wieder ein regulärer Ausdruck für Datumsangaben im Format 21.10.2005 oder 21.10.05. Da der einfache Punkt in regulären Ausdrücken die Bedeutung eines beliebigen Zeichens hat, muss hier \. geschrieben werden, um genau den Punkt zu spezifizieren.
#REG( ^[^0-9]*Uhr ) |
Gefunden werden hiermit Varianten von Uhr, bei denen zwischen dem Wortanfang und der Zeichenkette Uhr keine Ziffern vorkommen. Damit werden z.B. Angaben wie 19Uhr, 18.30Uhr etc. vermieden.
#REG( ^[^-]*bahn[^-]*$ ) |
Hiermit werden, unter Ausschluss jeglichen Bindestrichs, Wortbildungen von Bahn gesucht.
#REG( ^[^-]*bahn-[^-]*$ ) |
Durch das hinter bahn eingefügt - werden nun Wortbildung von bahn mit genau 1 Bindestrich gesucht. Gefunden werden z.B. Eisenbahn-Gesellschaft, bahn-übliche, etc..
#REG( ^[^-]{4,6}-[^-]{4,6}-[^-]{4,6}$ ) |
Gesucht werden hiermit Wortzusammensetzungen bestehend aus genau 2 Bindestrichen und drei Teilen mit 4 bis 6 Zeichen. Gefunden werden z.B. "Alte-Welt"-Wirt, "Sisi"-Gedenk-Kuchen, "Tante-Emma"-Laden, Zwölf-Punkte-Skala, etc.
#REG( ^[[:upper:]][[:lower:]]{2,5}[[:upper:]][[:lower:]]+ ) |
Sogenannte Zeichenklassen können in der Form [[:upper:]] oder
[[:digit:]] spezifiziert werden. Das obige Beispiel sucht nach Wortformen mit
mindestens 1 Binnenmajuskel nach folgendem Muster:
zuerst eine Majuskel, gefolgt von 2-5 Minuskeln, gefolgt von genau 1 Binnenmajuskel, gefolgt von mindestens 1 Minuskel.
Gefunden werden Wortformen wie AbiWord, ActionFirst, ÜberLeben, etc. aber auch ActionFormBean mit mehreren Binnenmajuskeln.
Weiterführendes Beispiel
#COND( #REG( ^Archi.*ung$ ), :-sa) |
Reguläre Ausdrücke können auf diese Art mittels des #COND()-Operators an bestimmten Positionen im Text gesucht werden. In diesem Beispiel werden Wortformen gefunden, die nicht am Satzanfang stehen.
Zu beachten ist in diesem Fall folgendes: der reguläre Ausdruck erzeugt in einem ersten Schritt eine temporäre Wortformliste zu ^Archiv.*ung$ ohne die Position im Text zu überprüfen. Erst im zweiten Schritt findet der Vorgang statt, der die Wortformen am Satzanfang rausfiltert.
Hinweis zu der Suche nach Umlauten, Zeichen mit Diakritika und dem ß
Das Modul für die Umsetzung der regulären Ausdrücke ist auf die westeuropäischen Sprachen von ISO-8859-1 (= Latein 1) eingestellt. Damit lassen sich Umlaute, Zeichen mit Diakritika und das ß zusammen mit den Zeichen des lateinischen Alphabets als Zeichenklassen abfragen, wie in der nachfolgenden Tabelle zu sehen ist. Achten Sie dabei ganz besonders auf das Problem mit dem ß.
| Klasse | Option Groß-/Klein | Umlaute | ß | andere Zeichen mit Diakr. | Kommentar |
|---|---|---|---|---|---|
[[:alpha:]]
| egal | ja | ja | ja | alphab. Zeichen |
[[:alnum:]]
| egal | ja | ja | ja | alphab. Zeichen und Ziffern |
[[:lower:]]
| egal | ja | ja | ja | alphab. Zeichen klein geschrieben |
[[:upper:]]
| egal | ja | nein | ja | alphab. Zeichen groß geschrieben; ß nicht als Großbuchstabe bekannt. |
[a-z]
| beachten
| ja | ja | ja | alphab. Zeichen klein geschrieben |
[a-z]
| ignorieren
| ja | nein! | ja | alphab. Zeichen klein geschrieben; Fehler: ß wird nicht gefunden! |
[a-zß]
| egal | ja | ja | ja | alphab. Zeichen klein geschrieben |
Hinweis zu den Klammern ( und )
Die runden Klammern werden innerhalb eines regulären Ausdrucks eingesetzt, um Alternativen auszudrücken, siehe dazu das Beispiel zu Redakteur. Achten Sie bitte darauf, die Klammern immer paarweise zu setzen, um Fehlermeldungen zu vermeiden.
Um runde Klammern als suchbare Zeichen einsetzen zu können, müssen diese in eckige
Bereichsklammern geschrieben werden, also z.B. [(] oder
mit anderen Zeichen zusammen, z.B. [()%$]. Beachten Sie, dass es in #REG
zum diesem Zweck nicht möglich ist, die Klammern als Escape-Sequenz \(
oder \) oder den gesamten Ausdruck zwischen "..." zu schreiben.
Behalten Sie bitte auch in diesem Zusammenhang im Hinterkopf, dass Klammern und sonstige Satzzeichen getrennt von Wortformen gespeichert sind und deshalb getrennt gesucht werden müssen. Deshalb führen in COSMAS II reguläre Ausdrücke, die Wortformen und Satzzeichen kombinieren, zu keinem Ergebnis.
Optionen
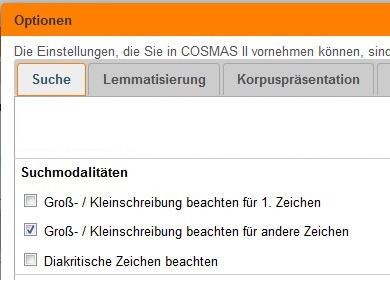
Suche - Suchmodalitäten
In dieser Optionskategorie wirkt sich einzig die Option Groß-/Kleinschreibung beachten für andere Zeichen ebenfalls auf die Auflösung von regulären Suchausdrücken aus: ist sie eingeschaltet, wird die Groß-/Kleinschreibung des regulären Ausdrucks berücksichtigt (empfohlen), andernfalls nicht.
Die beiden anderen Optionen der Suchmodalitäten haben hier keine Wirkung.
Suche - Expansionslisten und Begrenzung der Ergebnismenge
Die Optionen für die Expansionslisten und die Begrenzung der Ergebnismenge sind für reguläre Ausdrücke ebenfalls wirksam.
Wortformlisten und Listenoptionen
- Wortformlisten können verwaltet werden.
- Die Erzeugung von Wortformlisten mit
#REGkann zusätzlich mit Listenoptionen gesteuert werden. - Lesen Sie hier mehr über die automatische Segmentierung von langen Wortformlisten.
1: die in COSMAS II angebotenen regulären Ausdrücke entsprechen der erweiterten GNU-Implementation.
2.2. Logische Operatoren
Die logischen Operatoren UND,
ODER, NICHT arbeiten textweise.
ODEReignet sich vorwiegend dafür, mehrere Suchbegriffe in einem einzigen Suchlauf suchen zu lassen.UNDundNICHTsind in erster Linie nützlich, um sich eine neue Recherchebasis, ein benutzerdefiniertes Korpus, gezielt zusammenzustellen.
Der Operator UND
Wenn Suchbegriffe mit dem logischen Operator
UND verknüpft sind, findet
COSMAS II im aktiven Korpus die Texte,
in denen alle Suchbegriffe vorkommen.
Beispiel-Suchanfrage:
anscheinend und scheinbar
|
Mit dieser Suchanfrage liefert COSMAS II die Texte, in denen "anscheinend" und "scheinbar" vorkommen.
- In der KWIC-Übersicht und in den Belegen wird korrekterweise mitunter nur das eine oder das andere Suchwort angezeigt, obwohl beide Suchwörter gefunden wurden. In einem solchen Fall ist der Umfang des dargestellten Kontextes zu klein, um beide Suchwörter anzeigen zu können.
Der Operator ODER
Wenn Suchbegriffe mit dem logischen Operator ODER
verknüpft sind, findet COSMAS II im aktiven
Korpus alle Texte, in denen mindestens eines der Suchbegriffe vorkommt.
Beispiel-Suchanfrage:
anscheinend oder scheinbar
|
Mit dieser Suchanfrage liefert COSMAS II die Texte, in denen "anscheinend" oder "scheinbar" oder beide Suchwörter vorkommen.
Wenn Sie die Suchoption Weggelassener
Verknüpfungsoperator bedeutet auf logische
"oder"-Verknüpfung eingestellt haben, so können Sie die
Suchbegriffe auch ohne den Operator ODER einfach
aneinanderreihen:
anscheinend scheinbar
|
Diese Vorgehensweise ermöglicht, mehr Suchbegriffe im Fragefenster
unterzubringen. Das Suchergebnis ist dasselbe, als hätten Sie den
Operator ODER verwendet.
- In der KWIC-Übersicht und in den Belegen wird korrekterweise mitunter nur das eine oder das andere Suchwort angezeigt, obwohl beide Suchwörter gefunden wurden. In einem solchen Fall ist der Umfang des dargestellten Kontextes zu klein, um beide Suchwörter anzeigen zu können.
Der Operator NICHT
Mit dem logischen Operator NICHT werden alle
Texte vollständig aus dem Suchergebnis ausgeschlossen, in denen der
Suchbegriff, der in der Suchanfrage hinter
dem NICHT steht, mindestens einmal vorkommt.
Beispiel-Suchanfrage:
anscheinend nicht scheinbar
|
Mit dieser Suchanfrage schließt COSMAS II alle Texte vollständig aus dem Suchergebnis aus, in denen "scheinbar" mindestens einmal vorkommt. Sie erhalten also nur Texte, in denen "anscheinend" allein auftritt. Es ist zu bedenken, dass auch die Texte aus dem Suchergebnis ausgeschlossen werden, in denen "anscheinend" und "scheinbar" zusammen vorkommen.
Zum Auffinden eines Suchbegriffs, bei dem ein zweiter Suchbegriff in einem bestimmten Abstand nicht vorkommt, wird der trefferausschließende Abstandsoperator verwendet.
- Logische Operatoren als Suchbegriffe
2.3. Abstandsoperatoren
Abstandsoperatoren ermöglichen, nach zwei und mehr Suchbegriffen suchen zu lassen, die in einem bestimmten Abstand zueinander vorkommen (treffereinschließende Abstandsoperatoren) oder nicht vorkommen (trefferausschließende Abstandoperatoren).
Alle Operatoren können Sie ins Suchanfragefenster schreiben
(UND, ODER,
NICHT können mit großen oder kleinen Buchstaben im
Suchanfragefenster stehen; in den Beispiel-Suchanfragen wurden
grundsätzlich kleine Buchstaben verwendet).
Zu den Abstandsoperatoren gehören
- der Wortabstandsoperator
w, - der Satzabstandsoperator
sund - der Absatzabstandsoperator
p,
die sich jeweils in zwei Gruppen gliedern lassen:
- treffereinschließende Operatoren: ermöglichen die Suche nach zwei und mehr Suchbegriffen, die in einem bestimmten Abstand zueinander vorkommen,
- trefferausschließende Operatoren: ermöglichen die Suche nach einem Suchbegriff, bei dem in einem bestimmten Abstand ein zweiter Suchbegriff nicht vorkommt.
Mit einem Abstandsoperator geben Sie an, wie groß der Abstand von Suchbegriff zu Suchbegriff maximal sein oder in welchem Intervall er liegen soll.
Zusätzlich finden für diesen Operator die Optionen für die Gruppenbildung min und max zur Anwendung.
| Abstandstyp | Abstandsoperator | |
|---|---|---|
| treffereinschließend | trefferausschließend | |
| Wortabstand | /w.. |
%w.. |
| Satzabstand | /s.. |
%s.. |
| Absatzabstand | /p.. |
%p.. |
Anstelle der Pünktchen im jeweiligen Abstandsoperator setzen Sie eine Zahl als Wert für den gewünschten maximalen Abstand (z.B. /w1) oder zwei durch Doppelpunkt getrennte Zahlen als Wert für den gewünschten Intervallabstand (z.B. /w3:2) ein.
Multi-Abstände
Die oben genannten Wortabstände lassen sich miteinander kombinieren, um die gewünschten Belege noch besser einzuschränken. Dabei werden die Abstandsbedingungen ohne Leerstelle hintereinander und von einem Komma getrennt geschrieben:
ein /+w1,s0 Fest |
Mit dieser Suchanfrage läßt sich die Wortfolge ein Fest innerhalb von Sätzen suchen.
Beispiel-Suchanfragen:
Dach /s2 FachDach /+w1 FachDach /-w1:2 FachDach %p0 Fach |
Maximal- und Intervallabstand
- Enthält ein Abstandsoperator nur eine Zahl MAX, so ist der von Ihnen angegebene Abstand ein Maximalwert. Demzufolge sind alle gefundenen Suchbegriffe mit einem kleineren Abstand zueinander (inklusive 0-Abstand) als dem angegebenen ebenfalls Bestandteil des Suchergebnisses.
- Enthält ein Abstandsoperator zwei durch einen Doppelpunkt getrennte Zahlen MAX:MIN, so arbeitet der Abstandsoperator mit einer Intervallangabe. Demzufolge sind nur diejenigen Suchbegriffe Bestandteil des Suchergebnisses, deren Abstand im angegebenen Intervall liegt.
Treffer-Reihenfolge
Im Zusammenhang mit den Abstandsoperatoren können Sie vorgeben, in welcher Reihenfolge die Suchbegriffe in den Belegen auftreten sollen.
Das + (Pluszeichen) im Operator (z.B. /+w..)
bedeutet, dass das in der Suchanfrage zuerst stehende Suchbegriff auch im
Beleg vor dem zweiten Suchbegriff stehen soll.
Das - (Minuszeichen) im Operator (z.B. /-w.. ) bedeutet, dass
das in der Suchanfrage zuerst stehende Suchbegriff im Beleg
nach dem zweiten Suchbegriff stehen soll.
Ohne + und - ist die Reihenfolge der Suchbegriffe im Beleg beliebig.
Mit Hilfe des Plus- bzw. Minuszeichens in einem Abstandsoperator
haben Sie die Möglichkeit, die Treffergenauigkeit der Suchen zu erhöhen
(Beispiel: &fordern /+s0 heraus).
Einwort- und Mehrworttreffer
Der einschließende Abstandsoperator liefert in der Regel eine Liste von Mehrworttreffern, die aus den Texttreffern der beiden Suchbegriffen bestehen.
Beispiel-Suchanfrage:
Geist /+w2:10 Zeit
|
Die Mehrworttreffer bestehen in diesem Beispiel aus den Wortpaaren "Geist" und "Zeit".
In einigen Fällen kann ein Abstandsoperator auch einzelne Einworttreffer liefern, wenn beide Suchbegriffe das gleiche Textwort liefern und der Abstandsoperator das Verschmelzen beider Textwörter zu einem Treffer zulässt.
Beispiel-Suchanfrage:
&Geist /s0 &Zeit
|
Durch Anwendung des Grundformoperators liefern beide Suchbegriffe einige
identische Textwörter wie z.B. Zeitgeist. In diesem Fall führt
dies zur Ausführung der Kombination von "Zeitgeist /s0
Zeitgeist".
Da "Zeitgeist" - mit sich selbst kombiniert - immer auch im selben
Satz vorkommt,
wird in diesem Fall ein Einworttreffer zurückgeliefert.
Soll dies vermieden werden, muss ein Intervallabstand
eingesetzt werden (Bsp. &Geist /w1:6 &Zeit)
oder ein gerichteter Abstand
(&Geist /+s0 &Zeit).
Der ausschließende Abstandsoperator liefert ausschließlich eine Liste von Einworttreffern bestehend aus dem ersten Suchbegriff der Suchanfrage.
Beispiel-Suchanfrage:
&Geist %s0 &Zeit
|
In diesem Fall besteht die Ergebnisliste lediglich aus Texttreffern von &Geist.
- Grundsätzliches zu Ein- und Mehrworttreffern
Typische Fallen
Abstand /+w1:1 statt /+w1
Bei der Suche nach einem Muster wie "es scheint, dass es" wird der Suchbegriff "es" zweimal verwendet. Falls Sie dieses Muster mit der folgenden Suchanfrage suchen, werden Sie falsche Ergebnisse erhalten:
| (((es /+w1 scheint) /+w1 dass) /+w1 es) |
Obwohl COSMAS II korrekt gearbeitet hat, werden Sie unter den Ergebnissen folgende Textpassagen finden:
- (1) Doch es scheint, dass es sich der Vatikan... (richtig)
- (2) und es scheint, dass dieser Wellenschlag ... (falsch)
- (3) Ob als Produzent oder Musiker, es scheint, dass seine Leidenschaft... (falsch)
(2) und (3) werden von COSMAS II zurückgeliefert
werden, da die gewählte Formulierung die Kombination von "es scheint,
dass" und "es" mit der Bedingung /+w1,
die gleichbedeutend ist wie /+w0:1,
zulässt.
Die Bedingung /+w0 ist erfüllt,
da "es" innerhalb von "es, dass" erscheint.
Um diese Falle zu vermeiden, formulieren Sie das gesuchte Muster
wie folgt unter Einsatz von /+w1:1:
| (((es /+w1 scheint) /+w1 dass) /+w1:1 es) |
- Auch wenn Sie für das gesuchte Muster die Wörter anders
miteinander kombinieren, müssen Sie das erste "es" und "scheint, dass es"
mit dem Operator
/+w1:1verknüpfen.
| (es /+w1:1 (scheint /+w1 (dass /+w1 es))) |
Option Weggelassener Verknüpfungsoperator
In der folgenden Suchanfrage sind zwei Suchbegriffe ohne Abstandsoperator angegeben:
runder Tisch
|
Da in diesem Fall implizit zwei verschiedene Operatoren gemeint sein
können, nämlich
der Wortabstand /+w1 und der logische Operator
ODER, müssen Sie mit der Suchoption
Weggelassener Verknüpfungsoperator
(im Suchanfragefenster) den gewünschten Operator einstellen:
| Option Weggelassener Verknüpfungsoperator |
implizite Bedeutung |
|---|---|
![[Bildschirmausschnitt]](op-implicit-w1.jpg) |
runder /+w1 Tisch |
![[Bildschirmausschnitt]](op-implicit-oder.jpg) |
runder oder Tisch |
2.3.1. Der Wortabstandsoperator w
Mit diesem Operator können Sie vorgeben, dass nur solche Textstellen Treffer sind, in denen zwei und mehr Suchbegriffe in einem bestimmten maximalen Abstand von Wörtern vorkommen.
Beispiel-Suchanfrage:
Gegenwart /w4 Zukunft
|
Mit dieser Suchanfrage erhalten Sie Belege, in denen die Wörter
"Gegenwart" und "Zukunft" im Abstand von bis zu 4 Wörtern
vorkommen. In den Belegen kann "Zukunft" im Abstand von bis zu
4 Wörtern vor oder/und nach "Gegenwart" stehen, denn es wurde
keine Treffer-Reihenfolge
vorgegeben (kein +
oder - im Operator verwendet).
- Weitere Beispiele zur Suche nach Wortgruppen
Wortabstand und Satzzeichen
COSMAS II interpretiert Satzzeichen im Zusammenhang mit dem Wortabstand ähnlich wie Suchwörter. Der Abstand von einem Satzzeichen zu einem Wort ist folgendermaßen definiert:
- Ein Satzzeichen, das einem Wort unmittelbar nachgestellt ist, hat zu ihm einen Abstand von 0 Wörtern.
- Ein Satzzeichen, das einem Wort unmittelbar vorangestellt ist, hat zu ihm einen Abstand von 1 Wort.
In der Fügung "... das heißt, daß ..." hat das Komma zu "heißt" einen Abstand von 0 Wörtern, zu "daß" einen Abstand von 1 Wort.
Zielt Ihre Suche auf ein Suchwort mit unmittelbar nachgestelltem
Satzzeichen ab, können Sie den Wortabstands-Operator
in der Form /w0 (im Abstand von 0 Wörtern) einsetzen:
heißt /w0 ,
|
- Weitere Beispiele zur Suche nach Wörtern mit Satzzeichen
Wortabstand 0 und Überlappungen von Textbereichen
der 0-Wortabstand kann auch eingesetzt werden, um eine Überlappung zwischen mehreren Textbereichen zu erkennen. Dabei ist es nicht notwendig, dass die Textbereiche gemeinsame Wörter enthalten.
2.3.2. Der Satzabstandsoperator s
Mit diesem Operator können Sie vorgeben, dass nur solche Textstellen Treffer sind, in denen zwei und mehr Suchbegriffe innerhalb einer bestimmten maximalen Anzahl von Sätzen vorkommen.
Beispiel-Suchanfrage:
Gegenwart /s2 Zukunft
|
Mit dieser Suchanfrage erhalten Sie Belege, in denen Zukunft im Abstand von bis zu 2 Sätzen vor oder/und nach dem Satz, in dem Gegenwart gefunden wurde, vorkommt. Es wurde keine Treffer-Reihenfolge festgelegt (kein + oder - im Operator verwendet).
- Weitere Beispiele zur Suche innerhalb eines Satzes
- Beispiele zur Such nach trennbar zusammengesetzten Verben
2.3.3. Der Absatzabstandsoperator p
Mit diesem Operator können Sie vorgeben, dass nur solche Textstellen Treffer sind, in denen zwei und mehr Suchbegriffe innerhalb einer bestimmten maximalen Anzahl von Absätzen vorkommen.
Beispiel-Suchanfrage:
Gegenwart /p2 Zukunft
|
Mit dieser Suchanfrage erhalten Sie Belege, in denen "Zukunft"
im "Abstand" von bis zu 2 Absätzen vor oder/und nach dem Absatz,
in dem Gegenwart gefunden wurde, vorkommt.
Es wurde keine Treffer-Reihenfolge festgelegt
(kein + oder - im Operator verwendet).
2.4. Annotationsoperatoren
Annotationsoperatoren ermöglichen die Eingabe von linguistischen oder strukturellen Annotationen (z.B. Überschriften).
Zur Zeit wird als einziger Operator MORPH angeboten, der die Eingabe von Wortklassen für den jeweils in einem Archiv verwendeten Tagset unterstützt.
2.4.1. Operator MORPH
MORPH ist ein Operator für die Formulierung
von Wortklassen. Er kann sinnvollerweise nur in morphosyntaktisch annotierten Archiven
eingesetzt werden und unterstützt verschiedene Tagsets.
- Übersicht über die
Archive und Tagsets, in denen
MORPHgegenwärtig eingesetzt werden kann.
Beispiel-Suchanfrage:
MORPH(V PCP)
|
Eingabeassistent
Das Ausfüllen des MORPH-Operators wird meistens
durch einen
Eingabe-Assistenten unterstützt, damit das Nachschlagen der Wortklassen
und ihrer Unterklassen in der Online-Dokumentation entfallen kann.
Die obige Tabelle gibt an, ob für ein Archiv und das darin verwendete
Tagset ein Assistent in der jeweiligen COSMAS II-Applikation vorhanden ist.
Ist, wie im Fall von COSMAS IIwin, der Assistent in einem Archiv mit morphosyntaktisch annotierten Korpora nicht verfügbar, können die Wortklasseninformationen in den oben genannten Tagset-Dokumentationen nachgeschlagen und von Hand in den Operator MORPH eingetragen werden. Analog dazu können vom Assistent erzeugte MORPH-Ausdrücke nach Belieben von Hand verändert werden.
- Beschreibung des morphosyntaktischen Assistenten
Beispiel 2: Negieren einer Wortklasse
MORPH(-NOU)
|
Die Negation einer Wortklasse wird vom Assistenten nicht unterstützt, das Negationszeichen "-" muss von Hand eingetragen werden.
Ausdrücke mit negierten Wortklassen, im Gegensatz zu negierten Untermerkmalen, müssen wohlüberlegt eingesetzt werden, da sie eine temporäre Treffermenge großen Ausmaßes erzeugen; auf der einen Seite werden dadurch der Ressourcen des COSMAS II-Servers stark beansprucht, auf der anderen Seite wird die Ausführung der Suchanfrage verlangsamt.
Wiederholungsoptionen
Der MORPH-Operator läßt sich mit an regulären Ausdrücken angelehnter Syntax mit einer Wiederholungsoption effizient und mit einfacher Schreibweise wiederholen.
2.4.2. MORPH mit Wiederholungsoptionen
Mit einer an regulären Ausdrücken angelehnten Syntax
kann der Operator MORPH
für eine Sequenz von Wortklassen auf einfache Weise wiederholt werden:
MORPH(...){Wiederholungsfaktor,Bereiche}Nebst dem Wiederholungsfaktor sind ebenfalls die für COSMAS II typischen Satz- und Absatzbereiche spezifizierbar, in denen die Mehrworttreffer aufgefunden werden sollen.
Die Einzeloptionen sind die folgenden:
| Wiederholungsfaktor | Satzbereich | Absatzbereich |
|---|---|---|
| + | min | min:max | :max | Smax | Smin:max | Pmax | Pmin:max |
In den Suchanfragen werden min und max durch die gewünschten Werte ersetzt. Die Optionen können durch Leerstellen oder Kommata voneinander getrennt werden. Die Groß- und Kleinschreibung spielt keine Rolle.
Die Vorteile von MORPH{min:max} gegenüber dem klassischen
Wortabstandsoperator /w von COSMAS II besteht darin,
dass:
- sich mit ihm Wortklassensequenzen spezifizieren lassen, die sich dem Wortabstandsoperator nur umständlich bis gar nicht formulieren lassen,
- die Lesbarkeit der Suchanfrage entscheidend verbessert wird und
- die Antwortzeiten zum Teil deutlich kürzer sind.
Bedeutung der Optionen
| Options- gruppe |
Option | Bedeutung | Beispiel |
| + | min | min:max | :max | min | minimale Anzahl Wiederholungen. Default ist 1 und kann nicht unterschritten werden. | {3} |
| :max | maximale Anzahl Wiederholungen. | {:5} | |
| min:max | minimale und maximale Anzahl Wiederholungen. | {3:5} | |
| + | steht für min=1 und max=beliebig, ist also eine Kurzform für {1:}. | {+} | |
| Anm.: der Wiederholungsfaktor ist obligatorisch. Zu beachten: steht nur 1 Wert (ohne Doppelpunkt), handelt es sich um einen Minimalwert. | |||
| Smax | Smin:Smax | Smax | Der Wert max gibt den maximalen Satzbereich an. Default ist s0, d.h. innerhalb 1 Satzes. | {s0} |
| Smin:max | Die Werte min und max geben den minimalen und maximalen Satzbereich
an. Im Beispiel wird nach einer Sequenz gesucht, die sich über 2 Sätze erstrecken soll. | {s1:1} | |
| Anm.: der Satzbereich ist fakultativ. Der Default ist s0. Zu beachten: steht nur 1 Wert, handelt es sich um einen Maximalwert. | |||
| Pmax | Pmin:Pmax | Pmax | Der Wert max gibt den maximalen Absatzbereich an. Default ist p0, d.h. innerhalb 1 Absatzes. | {p0} |
| Pmin:max | Die Werte min und max geben den minimalen und maximalen Absatzbereich
an. Im Beispiel werden Sequenzen gesucht, die sich über 2 Absätze erstrecken sollen. | {p0:1} | |
| Anm.: der Absatzbereich ist fakultativ. Der Default ist p0. Zu beachten: steht nur 1 Wert, handelt es sich um einen Maximalwert. | |||
Die in den Satz- und Absatzbereichen einzusetzenden Werte werden von COSMAS II analog
zu den Satz- und Absatzabständen /s0, /s1:1, /p0, /p1:1 etc.
umgesetzt.
Beispiele
MORPH(A){2}
|
MORPH(A){2,s0p0}
|
Gesucht wird hier eine Sequenz von mindestens 2 Adjektiven. Die erste Formulierung ist gleichwertig mit der ausgeschriebenen Zweiten.
MORPH(A){2:4}
|
Gesucht wird hier eine Sequenz von 2 bis 4 Adjektiven.
MORPH(A){:5}
|
Gesucht wird hier eine Sequenz von 1 (= Default) bis 5 Adjektiven.
MORPH(A){+}
|
Gesucht wird hier eine Sequenz von mindestens 1 Adjektiv.
MORPH(A){+,s1}
|
Gesucht wird hier eine Sequenz von mindestens 1 Adjektiv in einem Bereich von maximal 2 Sätzen.
MORPH(A){+,s1:1}
|
Gesucht wird hier eine Sequenz von mindestens 1 Adjektiv in einem Bereich von genau 2 Sätzen.
- In den thematischen Beispielen findet sich ein weiterführender Fall als Kombination von Wortklassen mit Wiederholungsfaktor.
Wirkungsweise von MORPH{min:max}
Beim Einsatz von regulären Ausdrücken ist nicht immer eindeutig, welche Textbereiche als Treffer zurückgeliefert werden: Es muss entschieden werden, ob nur die ersten oder alle, die kürzesten oder die längsten, ob überlappende oder nicht-überlappende Fundstellen in die Trefferliste aufgenommen werden.
COSMAS II wendet hierbei folgende Regeln an:
- es werden alle möglichen Fundstellen geliefert, die den regulären Ausdruck erfüllen, überlappende inklusive;
- bei Angabe ungleicher Min- und Max-Werte werden die längst möglichen Fundstellen den kürzeren bevorzugt.
Die Anwendung dieser Regeln durch COSMAS II sei anhand der folgenden Textstelle bei der Suche diverser Adjektiv-Sequenzen veranschaulicht:
| Beleg: A10/JAN.03411: ..., die allesamt das heilige, geschützte, sündhaft teure Wort «Olympisch» im Namen trugen. |
| MORPH(A){min:max} | zurückgelieferte Treffer |
|---|---|
| MORPH(A){2:2} | heilige, geschützte geschützte, sündhaft sündhaft teure |
| MORPH(A){3:3} | heilige, geschützte, sündhaft geschützte, sündhaft teure |
| MORPH(A){2:3} | heilige, geschützte, sündhaft geschützte, sündhaft teure sündhafte teure |
| MORPH(A){1:4} | heilige, geschützte, sündhaft teure geschützte, sündhaft teure sündhaft teure teure |
Da längere Sequenzen gegenüber kürzeren bevorzugt werden, wird z.B. für
MORPH(A){1:4} die Sequenz »heilige, geschützte, sündhaft«
(3 Adjektive) zugunsten der längeren »heilige, geschützte, sündhaft teure«
herausgefiltert.
Vergleich von 'MORPH /+w MORPH' mit MORPH{min:max}
Für die Angabe von Wiederholungen mit min = max
gibt es eine entsprechende Suchanfrageformulierung mittels Wortabstand
/+w1:1,s0, die dieselben Treffer zurückliefert.
Zur Vereinfachung steht MORPH in der nachfolgenden Übersicht für
eine beliebige Wortklasse, z.B. MORPH(A):
| MORPH{1:1} | = | MORPH |
| MORPH{2:2} | = | MORPH /+w1:1,s0 MORPH |
| MORPH{3:3} | = | MORPH /+w1:1,s0 MORPH /+w1:1,s0 MORPH |
| etc. |
Für den Fall, dass min < max ist, gibt es zwei
alternative, äquivalente Formulierungen mit den üblichen Operatoren
/w und oder, die allerdings
zu unübersichtlichen und fehleranfälligen Formulierungen führen und außerdem
einige Extra-Treffer zurückliefern, die bei MORPH{min:max}
angenehmerweise unter den Tisch fallen, weil sie in längere Treffer aufgehen.
Einige Beispiele dazu:
| MORPH{1:2} | = | MORPH oder (MORPH /+w1:1,s0 MORPH) | Var. 1 |
| = | MORPH /+w0:1,s0 MORPH | Var. 2 | |
| MORPH{1:3} | = | MORPH oder (MORPH /+w1:1,s0 MORPH) oder (MORPH /+w1:1,s0 MORPH /+w1:1,s0 MORPH) | Var. 1 |
| = | ((MORPH /+w0:1,s0,min MORPH) /+w0:1,s0,min MORPH) /+w0:1,s0,min MORPH | Var. 2 | |
| MORPH{2:3} | = | (MORPH /+w1:1,s0,min MORPH) /+w1:1,s0,min (MORPH oder (MORPH /+w1:1,s0,min MORPH) oder (MORPH /+w1:1,s0,min MORPH /+w1:1,s0,min MORPH)) | Var. 1 |
| = | ((MORPH /+w1:1,s0,min MORPH) /+w0:1,s0,min MORPH) /+w0:1,s0,min MORPH | Var. 2 | |
| etc. |
Antwortzeiten von MORPH{min:max}
MORPH{min:max} liefert in mehrerer Hinsicht kürzere Antwortzeiten
als MORPH /w MORPH und ist, wo es möglich ist,
dem klassischen Operator vorzuziehen.
- Siehe dazu die durchgeführten Messreihen.
2.5. Kombinationsoperatoren
Zu den Kombinationsoperatoren gehören
2.5.1. Kombinationsoperator #IN
Definition
- Kurzform ohne Optionen:
X #IN Y - Vollständige Form mit Optionen:
X #IN(Optionen) Y
Mit #IN werden alle Vorkommnisse des (komplexen)
Suchbegriffes X gefunden, die sich innerhalb des gesuchten (komplexen)
Objektes Y befinden.
Obwohl es sich um einen Kombinationsoperator handelt, enthält das Resultat nur die Liste der Suchbegriffe X, die die Suchanfrage erfüllen.
Verwendung
Der Operator #IN stammt aus der Syntax für die grafische Eingabe
(wo er ohne # geschrieben wird) und wurde im August 2010 in die
Syntax für die zeilenorientierte Eingabe übernommen.
2.5.2. Kombinationsoperator #OV
Definition
- Kurzform ohne Optionen:
X #OV Y - Vollständige Form mit Optionen:
X #OV(Optionen) Y
Mit #OV werden alle Vorkommnisse des (komplexen) Suchbegriffes X gefunden, die sich mit den Vorkommnissen des gesuchten (komplexen) Suchbegriffes Y überschneiden (OV = overlay, dt. überschneiden).
Obwohl es sich um einen Kombinationsoperator handelt, besteht das Resultat nur aus den ausgewählten Vorkommnissen von X.
Einschränkung
Der Operator #OV erkennt Überlappungen von Textbereichen normalerweise
nur dann, wenn diese Bereiche mindestens 1 gemeinsames Wort haben. Um Überlappungen von Textbereichen
zu finden, die kein gemeinsames Wort haben, muss die Bereichsoption #OV(ALL)
eingeschaltet werden; alternativ kann auch zu diesem Zweck der 0-Wort-Abstandsoperator
/w0 eingesetzt werden.
- siehe dieses thematische Beispiel zum Auffinden von Überlappungen mittels /w0
Verwendung
Der Operator #OV stammt aus der Syntax für die grafische Eingabe
(wo er ohne # geschrieben wird) und wurde im August 2010 in die
Syntax für die zeilenorientierte Eingabe übernommen.
Beispiel mit Bereichsoption ALL
Um die Wirkungsweise von #OV (= der Default für #OV(HIT))
und #OV(ALL) zu veranschaulichen, gehen wir von folgender Suchanfrage aus:
| inmitten /w10,s0 getan |
Diese Suchanfrage liefert im W-Archiv zur Zeit die folgenden 16 Treffer:

Abb. 1: die 16 Treffer von obiger Suchanfrage
Um die Belege mit oder ohne Komma zu finden, setzt man #OV wie folgt ein:
| S1: (inmitten /w10,s0 getan) #OV , |
In Suchanfrage S1 wird #OV mit der Default-Einstellung eingesetzt und wirkt
wie #OV(HIT): er sucht nach den Treffern inmitten und getan (= den Treffern
in rot), die mit Komma geschrieben sind. Das ergibt die folgenden 10 Treffer aus der Abb. 1: 2-6, 9-11, 14
und 16.
| S2: (inmitten /w10,s0 getan) #OV(ALL) , |
S2: will man zusätzlich die Fälle finden, bei denen das Komma auch zwischen den Treffern
inmitten und getan steht, so muss man #OV(ALL) einsetzen. Auf diese Weise erhält
man zusätzlich zu den 10 Treffern von S1 die 4 neuen Treffer aus Abb. 1 mit
den Zeilennummern: 1, 8, 13 und 15 (insgesamt also 14 Treffer).
Bemerkung: S2 führt zu den selben Ergebnissen wie
(inmitten /w10,s0 getan) /w0 ,(inmitten /w10,s0 getan) #OV ,| S3: (inmitten /w10,s0 getan) #OV(%) , |
S3: will man umgekehrt die Fälle ausschließen, bei denen die Treffer inmitten
und getan mit Komma geschrieben sind, so muss man die Ausschließungsoption #OV(%)
einsetzen und erhält aus Abb. 1 die 6 folgenden Belege: 1, 7-8, 12-13 und 15. Zu beachten
ist, dass das Auftreten von Kommata zwischen den Treffern - wie in Zeile 1 - dadurch nicht
verhindert wird; das erreicht man mit S4.
| S4: (inmitten /w10,s0 getan) #OV(ALL %) , |
S4: will man zusätzlich zu S3 die Kommata auch zwischen den Treffern
inmitten und getan ausschließen, so muss man den ganzen Bereich zwischen den Treffern
mit #OV(ALL %) angeben. Dadurch schließt man 14 Belege aus und übrig bleiben lediglich
die beiden Belege aus Abb. 1: 7 und 12.
Bemerkung: S4 führt zu den selben Ergebnissen wie:
(inmitten /w10,s0 getan) %w0 ,(inmitten /w10,s0 getan) #OV(%) ,2.6. Elementoperatoren
Als Elementoperator existiert im Gegensatz zur COSMAS II-Syntax nur
- der Operator #ELEM.
2.6.1. Elementoperator #ELEM
Definition
#ELEM(Element- und Attributausdruck)
Hintergrund
#ELEM ist ein Operator für fortgeschrittene Suchanfragen, bei denen die SGML- bzw. XML-Kodierung
in den Korpora abgefragt werden kann. Voraussetzung ist natürlich, dass man diese Kodierungen bereits kennt.
Die XML-Kodierungen bestehen generell aus:
- einem Element,
- optional aus einem oder mehreren Attributen,
- die wiederum ein oder mehrere Werte haben könnten.
Siehe dazu die folgenden Beispiele.
Innerhalb von #ELEM sollte mindestens der Elementname des tags oder ein Attribut-Werte-Paar
spezifiziert werden. Darüber hinaus können beliebig viele weitere Attrbute und zu jedem Attribut beliebig viele
Werte angegeben werden. Implizit wird zwischen allen Angaben ein logisches UND angenommen.
Das Ungleichheitszeichen (Symbol ≠) zwischen einem Attribut und einem Wert
kann sowohl mit type != 'top' als auch mit type <> 'top' formuliert werden.
Im Gegensatz dazu ist der Operator MORPH ein Beispiel dafür, wie man die interne Korpus-Kodierung für den Benutzer transparent machen kann. Die komplizierte Kodierung der Wortklassen wie <w ana='V PCP...'> wird durch den Operator MORPH vereinfacht (z.B: MORPH(V PCP)) und durch den MORPH-Assistent benutzerfreundlich präsentiert.
Verwendung
Der Operator #ELEM stammt aus der Syntax
für die grafische Eingabe
(wo er ohne # geschrieben wird) und wurde im August 2010 in die
Syntax für die zeilenorientierte Eingabe übernommen.
#ELEM wird in der COSMAS II-Syntax auf mehrere Operatoren
wie ELEM, ATT und
AAND abgebildet.
Diese Operatoren werden jedoch in der C1-Syntax nicht benötigt,
da in einem #ELEM ein
Ausdruck mit beliebigen Attribut-Werte-Kombinationen frei ausgedrückt werden kann.
Beispiel 1: Eingabe eines Elementnamens
#ELEM(S)
|
Gesucht wird in diesem Fall durch Eingabe von 'S' nach dem SGML- bzw. XML-Tag <s> für Sätze.
Beispiel 2: Eingabe eines Elementnamens und eines Attribut-Werte-Paares
#ELEM(HEAD type='top')
|
Gesucht wird in diesem Beispiel mit dem Elementnamen 'HEAD', dem Attribut 'type' und dem Wert 'top' nach Dachüberschriften, die in den IDS-Korpora wie folgt kodiert werden: <head type='top'>.
Beispiel 3: Angabe mehrerer Attribut-Werte-Paare
#ELEM(DIV type='Zeitschrift' complete='Y' n='0')
|
Gesucht wird mit dieser Formulierung nach XML-Kodierung der Art <div type='Zeitschrift' n='0' ...>.
Beispiel 4: Angabe von negierten Attributswerten
#ELEM(W ANA <> 'A ADV')#ELEM(W ANA != 'A ADV')#ELEM(W ANA != 'A' ANA != 'ADV')
|
Diese Formulierungen sind äquivalent und suchen nach Wörtern (<w ...>), deren Wortklasse weder ein Adjektiv noch ein Adverb (CONNEXOR-Tagset) ist.
Diese 3 Beispiele dienen der Veranschaulichung, wie sich beliebige Werte von Attributen verneinen lassen. Eine einfachere und völlig äquivalente Suchanfrage lässt sich auf einer höheren Ebene mit dem MORPH-Operator wie folgt formulieren:
MORPH(-A -ADV)
|
Listenoptionen
- Die Erzeugung von Listen mit dem Operator
#ELEMkann zusätzlich mit Listenoptionen gesteuert werden; dazu setzen Sie den#BED-Operator ein.
2.7.1. Operator #LINKS bzw. #BEG
Definition
#LINKS(X)bzw.#BEG(X)
X kann eine beliebig komplexe Suchanfrage sein. #LINKS reduziert
jede Treffergruppe in der Ergebnismenge X auf das erste Wort der Gruppe.
Besteht X aus einem 1-Wort-Treffer, so liefert #LINKS einfach nur das Wort selbst zurück.
Beispiel-Suchanfrage:
#LINKS(MORPH(V) /+w1:2 Sonne)
|
Die Treffermenge dieser Mehrwortsuchanfrage, bei der das Verb vor dem Wort Sonne steht,
wird mit dem Operator #LINKS auf das erste Trefferwort, also das Verb, reduziert.
Verwendung
Der Operator #LINKS stammt aus der Syntax für die grafische Eingabe
(wo er ohne # geschrieben wird) und wurde im August 2010 in die
Syntax für die zeilenorientierte Eingabe übernommen.
2.7.2. Operator #RECHTS bzw. #END
Definition
#RECHTS(X)bzw.#END(X)
X kann eine beliebig komplexe Suchanfrage sein. #RECHTS reduziert
jede Treffergruppe in der Ergebnismenge X auf das letzte Wort der Gruppe.
Besteht X aus einem 1-Wort-Treffer, so liefert #RECHTS einfach nur das Wort selbst zurück.
Beispiel-Suchanfrage:
#RECHTS(geht /+w1:2 MORPH(N))
|
Die Treffermenge dieser Mehrwortsuchanfrage, bei der eine Kombination von geht
mit einem dahinter stehenden Nomen gesucht wird,
wird mit dem Operator #RECHTS auf das letzte Trefferwort, also das Nomen, reduziert.
Verwendung
Der Operator #RECHTS stammt aus der Syntax für die grafische Eingabe
(wo er ohne # geschrieben wird) und wurde im August 2010 in die
Syntax für die zeilenorientierte Eingabe übernommen.
2.7.3. Operator #INKLUSIVE bzw. #ALL
Definition
#INKLUSIVE(X)bzw.#ALL(X)
X kann eine beliebig komplexe Suchanfrage sein.
#INKLUSIVE transformiert
jede Treffergruppe aus X, die aus einzelnen Wörtern bestehen kann, in einen
einzigen Bereich, in welchem alle Wörter Treffer sind.
Besteht X aus einem 1-Wort-Treffer, so liefert #INKLUSIVE dasselbe Wort zurück.
Beispiel-Suchanfrage:
#INKLUSIVE(&gehen /+w1:10,s0 voran)
|
Die Mehrwortsuchanfrage liefert, durch Anwendung von #INKLUSIVE,
den ganzen Textbereich zwischen einer Verbform von gehen und
voran inklusive gehen und voran.
Verwendung
Der Operator #INKLUSIVE stammt aus der Syntax für die grafische Eingabe
(wo er ohne # geschrieben wird) und wurde im August 2010 in die
Syntax für die zeilenorientierte Eingabe übernommen.
2.7.4. Operator #EXKLUSIVE bzw. NHIT
Definition
#EXKLUSIVE(X)bzw.#NHIT(X)
X kann eine beliebig komplexe Suchanfrage sein.
#EXKLUSIVE liefert
den oder die Bereiche zurück, die zwischen den Wörtern von X stehen.
Besteht X aus einem 1-Wort-Treffer oder aus einer zusammenhängenden Gruppe
von Wörtern, so liefert #EXKLUSIVE für dieses X nichts zurück.
Die Ergebnisliste von #EXKLUSIVE ist also per Definition
kleiner oder gleich der Ergebnisliste von X.
Beispiel-Suchanfrage:
#EXKLUSIVE(&gehen /+w1:10,s0 voran)
|
Diese Mehrwortsuchanfrage liefert, durch Anwendung von #EXKLUSIVE, den Textbereich
zwischen einer Verbform von gehen und voran, unter Ausschluss von gehen und voran.
Verwendung
Der Operator #EXKLUSIVE stammt aus der Syntax für die grafische Eingabe
(wo er ohne # geschrieben wird) und wurde im August 2010 in die
Syntax für die zeilenorientierte Eingabe übernommen.
2.7.5. Operator #BED bzw. #COND
Definition
#BED(X, :Bed.:Bed:etc.)bzw.#COND(X, :Bed.:Bed.:etc.)
X kann eine beliebig komplexe Suchanfrage sein. Mit Bed. werden 1 oder mehrere Bedingungen wie:
- die Angabe der Textposition,
- ein Frequenzfilter oder
- eine Referenz auf ein Listsegment
formuliert. Diese Bedingungen werden in der Online-Hilfe als Listenoptionen beschrieben.
Beispiel-Suchanfrage:
#BED(MORPH(V), :+sa)
|
Mit dieser Suchanfrage wird durch Angabe einer Textposition nach Verben gesucht, die am Satzanfang stehen.
Verwendung
Der Operator #BED stammt aus der Syntax für die grafische Eingabe
(wo er ohne # geschrieben wird) und wurde im August 2010 in die
Syntax für die zeilenorientierte Eingabe übernommen.
3.1. Angabe von Satz- und Absatzgrenzen
Folgende Auszeichnungen können eingesetzt werden, um Suchanfragen an Satz- und Absatzgrenzen zu formulieren:
- <sa> : Satzanfang bzw. erstes Wort eines Satzes.
- <se> : Satzende bzw. letztes Wort eines Satzes.
- <pa> : Absatzanfang bzw. erstes Wort eines Absatzes.
- <pe> : Absatzende bzw. letztes Wort eines Absatzes.
Beispiele
MORPH(V) /w0 <se>
|
Mit dieser Suchanfrage liefert COSMAS II die Verben, die an Satzenden stehen.
im /w0 <pa>
|
Mit dieser Suchanfrage liefert COSMAS II die Textstellen, an denen im am Anfang eines Absatzes steht.
Nachteil
Der Nachteil dieser Art von Suchanfragen besteht darin, dass sie langsam sind. Deshalb sollte man, wo es möglich ist, die Alternativen 1 oder 2 anwenden.
Alternative 1: Angabe von Textpositionen hinter den Suchbegriffen
im:pa
|
Diese Suchanfrage nach der Wortform im macht sich eine Erweiterung zunutze, bei der gesuchte Wort- und Grundformen nach einem ':' um die Angabe von Textpositionen ergänzt werden können. Diese Art der Suchanfrage ist um ein Vielfaches schneller als die entsprechende Suchanfrage mit <pa>.
Alternative 2: Verwendung des Operators #BED
#BED(MORPH(V),se)
|
Ebenfalls eine schnellere Ausführungszeit wird mit dem Operator #BED erreicht.
4.1. Reguläre Ausdrücke
Generelles
Reguläre Ausdrücke, sei es auf der Ebene einzelner Wortformen oder auf Satzebene (Reihenfolge der Wörter bzw. syntaktischer Ebene), waren bislang in der Suchanfragesprache von COSMAS II nicht realisiert worden.
Auf Wortebene wurde mit der Version 4.5.11 des COSMAS II-Servers der Operator #REG() eingeführt, der diesbezüglich abhilfe verschafft.
Ein Grund für das Fehlen von regulären Ausdrücken auf Satzebene liegt darin begründet, dass sie sich für umfangreiche Korpora (mehrere Milliarden laufende Wortformen für das DeReKo-Korpus) nicht immer auf effiziente Weise (also kurze Antwortzeiten) umsetzen lassen. Ein Suchmuster wie [^NOU] (kein Nomen an dieser Stelle des Satzes) bedeutet in DeReKo, dass über 3 Mrd. Wörter in den Speicher geladen werden. Korpusrecherche-Systeme, die reguläre Ausdrücke anbieten, verwalten in der Regel nur höchstens einige Hundert Millionen laufenden Wortformen.
Auf dieser Seite möchten wir auf ein paar interessante Alternativen mittels der Suchanfragesprache von COSMAS II hinweisen. Es ist allerdings in Zukunft nicht ausgeschlossen, dass einige Aspekte regulärer Ausdrücke ihren Weg in COSMAS II finden werden.
Alternativen zu regulären Ausdrücken auf Wortebene
Auf Wortebene bietet COSMAS II mit Platzhaltern (siehe hier für die grafischen Operatoren), auch Wildcards genannt, eine intuitive und vereinfachte Form von regulären Ausdrücken an, um Suchbegriffe flexibel über Teil-Zeichenketten zu formulieren.
Des weiteren bietet der Lemmatisierungs- bzw. Grundformoperator (siehe hier für die grafischen Operatoren) eine morphologisch fundierte Möglichkeit an, Derivationen, Flexionsformen und Komposita von Grundformen auszudrücken. Hierbei können auch Suffixe (z.B. "&-schaft") und Präfixe (z.B. "&ab-") auf diese Weise recherchiert werden.
Alternativen zu regulären Ausdrücken auf Satzebene
Der MORPH-Operator mit seinen Wiederholungsoptionen bietet die Möglichkeit an, variable und feste Sequenzen einer Wortklasse zu formulieren und effizient zu recherchieren.
Einige Formulierungen für die Reihenfolge von Wortformen, die sich mittels regulärer Ausdrücke formulieren lassen, können auch alternativ mit den vielfältigen Abstandsoperatoren (siehe hier für die grafischen Operatoren) ausgedrückt werden.
In der Folge werden einige Fälle von regulären Suchausdrücken vorgestellt, die sich direkt oder indirekt mittels der bestehenden COSMAS II-Operatoren ausdrücken lassen:
| regulärer Ausdruck1 | COSMAS II-Suchausdruck |
|---|---|
| &gehen []? heim | &gehen /+w2 heim |
| &gehen []* nach Hause | &gehen /+s0 (nach /+w1,s0 Hause) |
| &gehen []{1,3} heim | &gehen /+2:4w,s0 heim |
| (&gehen heim) | (heim &gehen) | &gehen /+w,s0 heim |
| DET [^ADJ] N | (MORPH(DET) %+w1:1,s0 MORPH(ADJ)) /+w2:2,s0 MORPH(N) |
| DET [^ADJ]{2,3} N | (MORPH(DET) /+w3:4,s0 MORPH(N)) %w0 MORPH(ADJ) |
| DET [^ADJ] | MORPH(DET) /+w1:1,s0 MORPH(-ADJ) |
- Reguläre Ausdrücke erzeugen Wortformlisten, die gespeichert und wiedereingesetzt werden können.
1 Reguläre Ausdrücke in der Korpuslinguistik verwenden oft [] für eine unspezifizierte Wortposition. [^ADJ] bedeutet hier: an dieser Wortposition kein Adjektiv.
4.2. Sonderzeichen in Suchanfragen
Zeichensatz Latin-1
Für die Formulierung von Suchanfragen in COSMAS II wird der allgemein bekannte Zeichensatz Latin-1 (offiziell: ISO 8859-1) eingesetzt, mit dessen Hilfe sich die 12 westeuropäischen Sprachen kodieren lassen1.
Zeichen in Latin-1 werden direkt über die Tastatur eingeben. Sofern ein Zeichen nicht auf der Tastatur abgebildet ist, kann es über den Zahlenblock anhand seines numerischen Codes in Latin-1 eingegeben werden.
Hinweis: die in HTML verwendeten Zeichennamen bzw. Entitäten wie z.B. É oder der numerische UNICODE-Wert wie z.B. É können für die Zeichen von Latin-1 nicht verwendet werden.
Beispiel
Das Zeichen großes E mit accent aigu, also É, kann über seinen numerischen Code ALT-0201 eingegeben werden. Im Eingabefenster von COSMAS II erscheint das gewünschte Zeichen.
Zeichen außerhalb von Latin-1
Zeichen und Sonderzeichen, die nicht durch Latin-1 abgedeckt sind, werden in COSMAS II mit Hilfe ihrer numerischen2 UNICODE-Kodierung verwaltet. Sie müssen dementsprechend auch so eingegeben werden.
Beispiel
Die französische Ligatur œ wird als Zeichenkette mit ihrem numerischen UNICODE-Wert œ eingegeben.
Beispiel
Für das Wort Œuvre wird die Eingabe "œuvre" zwischen Anführungszeichen geschrieben, da das & zu Beginn des Wortes ansonsten von COSMAS II als Lemmatisierungsoperator verstanden wird.
Siehe auch
Siehe auch das ausführliche Beispiel zu Apostrophen in Suchanfragen.
Kodierung von Sonderzeichen
Die Kodierung der Sonderzeichen und wie man sie über die Tastatur eingibt, kann man oft über ihre Artikelseite in Wikipedia erfahren. Z.B. die Artikelseite zum Auslassungszeichen bzw. den Auslassungspunkten enthält sowohl die Kodierung in dezimaler Schreibweise (verträglich mit COSMAS II) im Abschnitt Kodierung als auch im Abschnitt Tastatur, wie es direkt über die Tastatur eingegeben werden kann.
Das Et-Zeichen &
Eine Ausnahme innerhalb ISOlat1 bildet das Et-Zeichen '&', das wegen seiner Funktion in HTML- und UNICODE-Zeichenkodierungen als & kodiert ist und als solches gesucht werden muss.
| H&M-Kette |
Diese Suchanfrage findet Vorkommnisse von H&M-Kette.
Wird das & als freistehendes Zeichen und nicht als Bestandteil eines Wortes gesucht, muss es zwischen " und " geschrieben werden:
| Bang "&" Olufsen |
1Im Gegensatz zum unter WINDOWS verwendeten Zeichensatz WINDOWS-1252 sind die französischen Ligaturen œ und Œ nicht Teil von Latin-1.
2UNICODE-Kodierung: in COSMAS II wird die dezimale Schreibweise benutzt, z.B. É und nicht die hexadezimale, z.B. É, wo der Hexadezimalwert xc9 dem Dezimalwert 201 entspricht.
4.3. Listensegmente für unbegrenzte Wortformlisten
Hintergrund
Durch das stetige Anwachsen des
DeReKo-Korpus erzeugen die Wortformoperatoren
immer längere Listen von Wortformen (in COSMAS II auch Expansionslisten oder
temporäre Wortformlisten genannt). Wenn diese Listen einige Hunderttausend
Einträge oder mehr erreichen, wird es einerseits fast unmöglich, diese manuell auszuwerten.
Anderseits belasten sie auch den COSMAS II-Server und die Suchzeit kann einige Stunden in Anspruch
nehmen. Bei Erreichen eines intern festgelegten Zeitlimits bricht die Suche ohnehin
automatisch ab.
Um diese unerwünschten Effekte zu verhindern, werden überlange Wortformlisten automatisch abgeschnitten bzw. segmentiert, damit wenigstens ein Teil der Wortformlisten und somit die gesamte Suchanfrage Treffer erzielen kann.
Ein Fallbeispiel
- Größe von Archiv W (
DeReKo-Release 2018/II): 37 Mio. Texte, 11 Mrd. laufende Wortformen.
Bemerkung: Archiv W umfasst ca. 1/4 des gesamtenDeReKo. - Suche nach den Komposita des Affixes -ung: &-ung → Liste mit 21.006.850 Wortformen.
- Dauer für den Aufbau dieser Wortformliste mit Worthäufigkeiten: 6 Min.
- Recherche nach den Belegen für diese Wortformliste: mehr als 6 Std. Wegen des internen Zeitlimits bricht die Suche schon vorher ab.
Anmerkung: Um die interne Begrenzung zu vermeiden, könnte eine Alternative darin bestehen, nicht das gesamte Archiv W zu nutzen, sondern eine Auswahl von Texten und Korpora zu aktivieren.
Segmentierte Wortformlisten
Sie erkennen, dass eine Wortformliste abgeschnitten bzw. segmentiert wurde, wenn die Größe der Liste wie folgt angegeben ist:
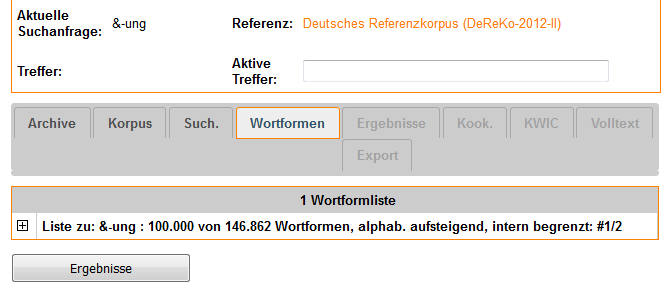
Erläuterung: Von der Gesamtliste, die 146.862 Wortformen umfasst, wurden nur 100.000 Wortformen in die Liste aufgenommen. Es wird darauf hingewiesen, dass dies auf eine interne Begrenzung zurückzuführen ist. Per Default wird von der Gesamtmenge das erste Segment zurückgeliefert, wie von #1/2 angegeben ist. Insgesamt besteht die gesamte Liste aus zwei Segmenten.
In der Exportdatei werden die begrenzten Wortformlisten auf genau dieselbe Weise gekennzeichnet.
Referenzieren eines Listensegments
Die Referenz auf ein Listensegment wird mit folgender Syntax ausgedrückt:
:#Zahl
wobei Zahl die Nummer des Segments ist.
Die Segmentnummer wird als Listenoption nach einem ':' ans Ende des Suchbegriffes angehängt
(auf ähnliche Weise wird die
Position des Suchbegriffes im Text angegeben). Werden sowohl Position als auch
Segmentnummer angegeben, so muss die Segmentnummer am Ende stehen (siehe Beispiele).
Das 1. Segment wird mit #1 angesprochen. Per Default wird auch automatisch
das 1. Segment zurückgeliefert.
Beispiele
Ansprechen von Segment #2 für eine Lemma-Suche:
| &-ung:#2 |
Referenzieren von Segment #2 und Angabe von Trefferposition = am Satzende:
| &-ung:se:#2 |
Ansprechen von Segment #2 für einen Suchbegriff mit Platzhalteroperatoren:
| Be*ung*:#2 |
Ansprechen von Segment #2 für den regulären Ausdruck
#REG muss allerdings mittels des Bedingungsoperators
#COND (bzw. #BED)
angegeben werden:
| #COND(#REG(^Be.*ung), :#2) |
Beachten Sie bitte, dass das direkte Anfügen der Segmentnummer an den
#REG-Operator nicht realisiert ist:
| #REG(^Be.*ung):#2 → nicht realisiert. |
Beachten Sie ebenfalls, dass Sie die Segmentnummer auch nicht innerhalb des
#REG-Ausdrucks spezifizieren können:
| #REG(^Be.*ung:#2) → nicht realisiert. |
Berechnung der relativen Worthäufigkeiten
Die normale Darstellung von ungekürzten Wortformlisten ist die folgende:
| Liste zu: Be*ung : 2.301 Wortformen, aphab. aufsteigend | ||
|---|---|---|
| (Auszug) ... | ||
| Bezirksverordnetenversammlung | 19 | (0.01%) |
| Bezirksversammlung | 30 | (0.02%) |
| Bezirksverwaltung | 96 | (0.06%) |
Zu jeder Wortform wird ihre absolute Frequenz (2. Spalte) im aktiven Korpus angezeigt. Diese Angabe ist unabhängig davon, wie oft die Wortform am Endergebnis der Suchanfrage beteiligt ist. Z.B. hat Bezirksverwaltung eine Frequenz von 19 im aktiven Korpus, aber je nach Suchanfrage, in die die Wortliste eingebettet ist, kann Bezirksverwaltung eine kleinere Frequenz im Endergebnis haben oder sogar ganz aus der Ergebnismenge verschwinden.
Zusätzlich wird die relative Häufigkeit (3. Spalte) berechnet. Diese stellt den
relativen Anteil dieser Wortform an der Gesamtfrequenz der Liste dar. Wenn also z.B. alle
Wortformen von Be*ung im aktiven Korpus zusammen 170.677 Mal vorkommen,
dies entspricht der Gesamtfrequenz der Liste, so beträgt der Anteil von Bezirksverwaltung
daran (69 / 170.677) * 100 = 0,06%.
Auch bei segmentierten Wortformlisten werden die absoluten und die relativen Häufigkeiten angezeigt. Dabei dürfen Sie davon ausgehen, dass die relativen Frequenzen sich auf die Gesamtliste beziehen, nicht nur auf das Segment, das Sie von der abgeschnittenen Liste zu sehen bekommen. Mit anderen Worten, um beim Beispiel mit Bezirksverwaltung zu bleiben, würden auch im entsprechenden Listensegment 96 für die absolute und 0.06% für die relative Häufigkeit angezeigt werden.