| Syntax der Zeileneingabe → Suchoperatoren → Wortformoperatoren → Listenoptionen → Segmentierte Wortformlisten |
Listensegmente für unbegrenzte Wortformlisten
Hintergrund
Durch das stetige Anwachsen des
DeReKo-Korpus erzeugen die Wortformoperatoren
immer längere Listen von Wortformen (in COSMAS II auch Expansionslisten oder
temporäre Wortformlisten genannt). Wenn diese Listen einige Hunderttausend
Einträge oder mehr erreichen, wird es einerseits fast unmöglich, diese manuell auszuwerten.
Anderseits belasten sie auch den COSMAS II-Server und die Suchzeit kann einige Stunden in Anspruch
nehmen. Bei Erreichen eines intern festgelegten Zeitlimits bricht die Suche ohnehin
automatisch ab.
Um diese unerwünschten Effekte zu verhindern, werden überlange Wortformlisten automatisch abgeschnitten bzw. segmentiert, damit wenigstens ein Teil der Wortformlisten und somit die gesamte Suchanfrage Treffer erzielen kann.
Ein Fallbeispiel
- Größe von Archiv W (
DeReKo-Release 2018/II): 37 Mio. Texte, 11 Mrd. laufende Wortformen.
Bemerkung: Archiv W umfasst ca. 1/4 des gesamtenDeReKo. - Suche nach den Komposita des Affixes -ung: &-ung → Liste mit 21.006.850 Wortformen.
- Dauer für den Aufbau dieser Wortformliste mit Worthäufigkeiten: 6 Min.
- Recherche nach den Belegen für diese Wortformliste: mehr als 6 Std. Wegen des internen Zeitlimits bricht die Suche schon vorher ab.
Anmerkung: Um die interne Begrenzung zu vermeiden, könnte eine Alternative darin bestehen, nicht das gesamte Archiv W zu nutzen, sondern eine Auswahl von Texten und Korpora zu aktivieren.
Segmentierte Wortformlisten
Sie erkennen, dass eine Wortformliste abgeschnitten bzw. segmentiert wurde, wenn die Größe der Liste wie folgt angegeben ist:
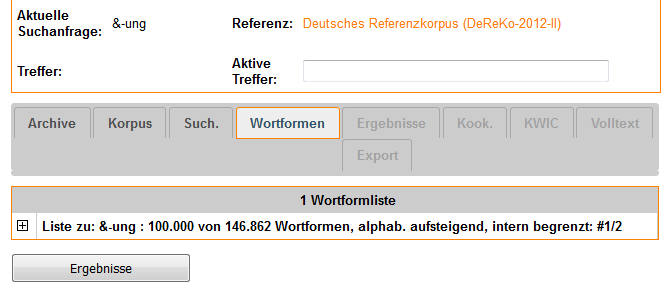
Erläuterung: Von der Gesamtliste, die 146.862 Wortformen umfasst, wurden nur 100.000 Wortformen in die Liste aufgenommen. Es wird darauf hingewiesen, dass dies auf eine interne Begrenzung zurückzuführen ist. Per Default wird von der Gesamtmenge das erste Segment zurückgeliefert, wie von #1/2 angegeben ist. Insgesamt besteht die gesamte Liste aus zwei Segmenten.
In der Exportdatei werden die begrenzten Wortformlisten auf genau dieselbe Weise gekennzeichnet.
Referenzieren eines Listensegments
Die Referenz auf ein Listensegment wird mit folgender Syntax ausgedrückt:
:#Zahl
wobei Zahl die Nummer des Segments ist.
Die Segmentnummer wird als Listenoption nach einem ':' ans Ende des Suchbegriffes angehängt
(auf ähnliche Weise wird die
Position des Suchbegriffes im Text angegeben). Werden sowohl Position als auch
Segmentnummer angegeben, so muss die Segmentnummer am Ende stehen (siehe Beispiele).
Das 1. Segment wird mit #1 angesprochen. Per Default wird auch automatisch
das 1. Segment zurückgeliefert.
Beispiele
Ansprechen von Segment #2 für eine Lemma-Suche:
| &-ung:#2 |
Referenzieren von Segment #2 und Angabe von Trefferposition = am Satzende:
| &-ung:se:#2 |
Ansprechen von Segment #2 für einen Suchbegriff mit Platzhalteroperatoren:
| Be*ung*:#2 |
Ansprechen von Segment #2 für den regulären Ausdruck
#REG muss allerdings mittels des Bedingungsoperators
#COND (bzw. #BED)
angegeben werden:
| #COND(#REG(^Be.*ung), :#2) |
Beachten Sie bitte, dass das direkte Anfügen der Segmentnummer an den
#REG-Operator nicht realisiert ist:
| #REG(^Be.*ung):#2 → nicht realisiert. |
Beachten Sie ebenfalls, dass Sie die Segmentnummer auch nicht innerhalb des
#REG-Ausdrucks spezifizieren können:
| #REG(^Be.*ung:#2) → nicht realisiert. |
Berechnung der relativen Worthäufigkeiten
Die normale Darstellung von ungekürzten Wortformlisten ist die folgende:
| Liste zu: Be*ung : 2.301 Wortformen, aphab. aufsteigend | ||
|---|---|---|
| (Auszug) ... | ||
| Bezirksverordnetenversammlung | 19 | (0.01%) |
| Bezirksversammlung | 30 | (0.02%) |
| Bezirksverwaltung | 96 | (0.06%) |
Zu jeder Wortform wird ihre absolute Frequenz (2. Spalte) im aktiven Korpus angezeigt. Diese Angabe ist unabhängig davon, wie oft die Wortform am Endergebnis der Suchanfrage beteiligt ist. Z.B. hat Bezirksverwaltung eine Frequenz von 19 im aktiven Korpus, aber je nach Suchanfrage, in die die Wortliste eingebettet ist, kann Bezirksverwaltung eine kleinere Frequenz im Endergebnis haben oder sogar ganz aus der Ergebnismenge verschwinden.
Zusätzlich wird die relative Häufigkeit (3. Spalte) berechnet. Diese stellt den
relativen Anteil dieser Wortform an der Gesamtfrequenz der Liste dar. Wenn also z.B. alle
Wortformen von Be*ung im aktiven Korpus zusammen 170.677 Mal vorkommen,
dies entspricht der Gesamtfrequenz der Liste, so beträgt der Anteil von Bezirksverwaltung
daran (69 / 170.677) * 100 = 0,06%.
Auch bei segmentierten Wortformlisten werden die absoluten und die relativen Häufigkeiten angezeigt. Dabei dürfen Sie davon ausgehen, dass die relativen Frequenzen sich auf die Gesamtliste beziehen, nicht nur auf das Segment, das Sie von der abgeschnittenen Liste zu sehen bekommen. Mit anderen Worten, um beim Beispiel mit Bezirksverwaltung zu bleiben, würden auch im entsprechenden Listensegment 96 für die absolute und 0.06% für die relative Häufigkeit angezeigt werden.