Die Zeitverlaufsgrafiken, ein Ergebnis der Kooperation zwischen den IDS-Projekten Neuer Wortschatz und Methoden der Korpusanalyse und
-erschließung, basieren auf den nachfolgend beschriebenen Korpusdaten und Suchanfragen. Zeitverlaufsgrafiken werden in zwei Ansichten angeboten, die hier ebenfalls kurz charakterisiert
werden. Beim Betrachten und Interpretieren der Zeitverlaufsgrafiken sind zudem zwei grundlegende
Hinweise zur statistischen Zuverlässigkeit zu beachten.
Die Beziehung zwischen den Grafiken und den Artikeln des Onlinewörterbuchs wird in den Anmerkungen des Projekts
Neuer Wortschatz kurz umrissen.
Datengrundlage
Den Zeitverlaufsgrafiken liegt ein virtuelles Korpus zugrunde, das alle Zeitungskorpora
im Deutschen Referenzkorpus
(DeReKo)[1] im COSMAS II-Archiv W (Archiv der geschriebenen
Sprache) seit 1990 umfasst. Zeitungskorpora sind im vorliegenden Kontext besonders geeignet,
u.a. weil sie der Allgemeinsprache zuzurechnen sind und gleichzeitig einen zeitlich
kontinuierlichen Datenstrom darstellen. Dieses virtuelle Korpus umfasst derzeit insgesamt ca.
9,15 Milliarden laufende Textwörter, die sich auf die einzelnen Jahrgänge verteilen,
wie in der folgenden Abbildung dargestellt. Der gewünschte Zeitraum ist durch dieses Korpus
lückenlos und für jedes Jahr substanziell abgedeckt, wobei der Korpusumfang zwischen
den einzelnen Jahren sichtbar variiert.
[1]
Leibniz-Institut für Deutsche Sprache
(2021): Deutsches Referenzkorpus / Archiv der Korpora geschriebener Gegenwartssprache
2021-I (Release vom 2.2.2021). Mannheim: Leibniz-Institut für Deutsche Sprache. www.ids-mannheim.de/DeReKo
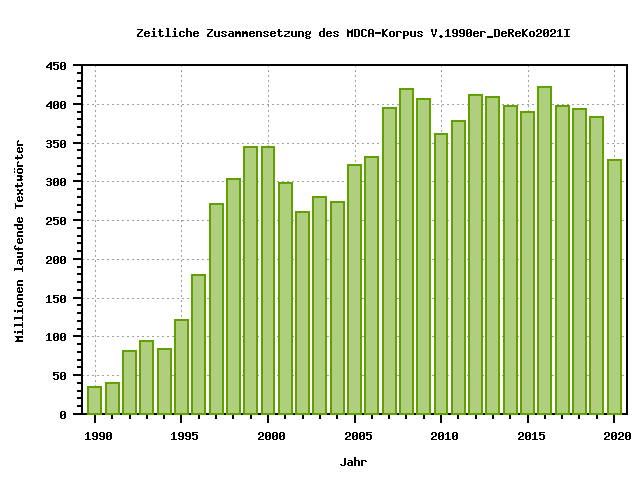
Abbildung: Korpusumfang nach Jahren
Die Korpustexte stammen aus Deutschland, aus Österreich, aus der Schweiz sowie zu
einem kleinen Anteil aus Luxemburg. Aus dem Gesamtkorpus leiten sich die für die drei
für die Zeitverlaufsgrafiken im Neologismenwörterbuch betrachteten Teilkorpora her:
Für die Neologismen der 1990er Jahre das Gesamtkorpus der Jahre 1990-2020, für die
Neologismen der 2000er Jahre das Teilkorpus der Jahre 2001-2020 und für die Neologismen der
2010er Jahre das Teilkorpus der Jahre 2011-2020. Die Größen der Teilkorpora sind nach
Ländern aufgeschlüsselt die folgenden:
|
Gesamtkorpus 1990-2020
für Neologismen der 1990er |
Teilkorpus 2001-2020
für Neologismen der 2000er |
Teilkorpus 2011-2020
für Neologismen der 2010er |
| |
Tokens |
Länderanteil |
Tokens |
Länderanteil |
Tokens |
Länderanteil |
| TOTAL |
9,15 Milliarden |
100,00 % |
7,25 Milliarden |
100,00 % |
3,90 Milliarden |
100,00 % |
| DE |
6,36 Milliarden |
69,53 % |
5,13 Milliarden |
70,80 % |
2,73 Milliarden |
69,84 % |
| AT |
1,22 Milliarden |
13,31 % |
0,72 Milliarden |
9,91 % |
0,41 Milliarden |
10,58 % |
| CH |
1,50 Milliarden |
16,38 % |
1,33 Milliarden |
18,32 % |
0,70 Milliarden |
17,98 % |
| LU |
0,07 Milliarden |
0,78 % |
0,07 Milliarden |
0,98 % |
0,06 Milliarden |
1,60 % |
Zu beachten ist, dass die Texte aus der Schweiz den Zeitraum 1990-1995 nicht abdecken,
die Texte aus Luxemburg den Zeitraum von 1990-1999 nicht abdecken und die österreichischen
Texte den Zeitraum von 2001 bis 2006 nur schwach abdecken. Die bundesdeutschen Texte hingegen
decken den gesamten Zeitraum von 1990 bis heute substanziell ab. Bei Wörtern, deren
Gebrauchshäufigkeit in den drei Sprachräumen Deutschland, Österreich und Schweiz
deutlich unterschiedlich ausgeprägt ist und eine unterschiedliche zeitliche Entwicklung
aufweist, kann die lückenhafte Abdeckung durch Texte aus Österreich und der Schweiz
dazu führen, dass die zugehörige Zeitverlaufsgrafik große Sprünge aufweist.
Das zeigt sich z.B. bei der Zeitverlaufsgrafik zum Wort Folder, das in den österreichischen
Texten deutlich stärker verbreitet ist als etwa in den bundesdeutschen.
Suchanfragen
Die in den Zeitverlaufsgrafiken dargestellte zeitliche Verteilung der
Gebrauchshäufigkeit des jeweiligen Wortes ist das Ergebnis einer entsprechenden Suchanfrage
via COSMAS II an das o.g. Korpus. Diese
Suchanfrage wurde heuristisch formuliert durch eine explizite Auflistung aller Zeichenketten
(ggf. flektierte Wortformen und orthografische Varianten), die dem jeweiligen
Neologismus-Stichwort zuzurechnen sind. Sie wurde vollautomatisch durchgeführt, eine
manuelle Kontrolle der jeweiligen Treffermenge fand nur anhand kleiner Stichproben statt. Daher
ist nicht auszuschließen, dass die Treffermengen für einzelne Wörter
systematisch fehlerhafte Treffer enthalten (false positives) oder bestimmte Arten von
gewünschten Belegen systematisch nicht enthalten (false negatives). Diese
Möglichkeit trägt zusätzlich zu anderen Faktoren dazu bei, dass die
resultierenden Zeitverlaufsgrafiken die tatsächliche zeitliche Entwicklung der
Gebrauchshäufigkeit des jeweiligen Wortes im gegebenen Korpus nicht immer adäquat
wiedergeben.
In dem konkreten Fall der beiden Neulexeme die
Ex und der
Ex war es kaum möglich, eine
Suchanfrage zu formulieren, die gezielt nach den Vorkommen des einen Lexems sucht, ohne
gleichzeitig auch einen Großteil der Vorkommen des anderen Lexems zu finden. Aus diesem
Grund wurde schließlich eine einzige Suchanfrage verwendet, die nach den Vorkommen beider
Neulexeme sucht, so dass die beiden entsprechenden Zeitverlaufsgrafiken identisch sind.
Zwei Arten von Zeitverlaufsgrafiken
Für jedes Neologismus-Stichwort wird der berechnete Zeitverlauf seiner
Gebrauchshäufigkeiten in zwei Ansichten angeboten: Während die Standard-Ansicht (relative
Häufigkeit) intuitiv zugänglicher und daher zum schnellen Erfassen der
zeitlichen Entwicklung eines Wortes besser geeignet ist, erlaubt die alternative Ansicht (Differenzenkoeffizient) tiefer gehende Interpretationen und insbesondere
unmittelbare visuelle Vergleiche zwischen verschiedenen Zeitverläufen. In dieser zweiten
Ansicht ist zusätzlich zum Differenzenkoeffizienten die relative Häufigkeit auf einer
zweiten y-Achse aufgetragen, hierdurch können beide Ansichten leichter zueinander in
Beziehung gesetzt werden. Für allgemeine Beschreibungen zu diesen (und weiteren)
Häufigkeitsmaßen sei auf Keibel (2008) verwiesen.
Statistische Zuverlässigkeit: Häufigkeitsklasse
Grundsätzlich zu beachten ist der folgende vereinfachte Zusammenhang: Je seltener
ein Wort im gegebenen Korpus insgesamt vorkommt, desto stärker hängt der beobachtete
zeitliche Verlauf seiner Gebrauchshäufigkeit von zufälligen Faktoren ab, d.h., desto
weniger zuverlässig gibt die entsprechende Zeitverlaufsgrafik die tatsächliche
zeitliche Entwicklung im Gebrauch dieses Wortes wieder. Aus diesem Grund wird mit jeder
Zeitverlaufsgrafik die Gesamthäufigkeit des jeweiligen Wortes im gesamten Korpus (also
über alle Jahrgänge) in Form einer Häufigkeitsklasse angegeben, deren Wert umso niedriger ist, je
häufiger das Wort insgesamt vorkommt. Für das aktuelle Korpus lässt sich die
folgende Faustregel formulieren: Die Zeitverlaufsgrafiken von Wörtern mit einer
Häufigkeitsklasse von 22 oder höher sind i.A. zu unzuverlässig, um sinnvoll
interpretiert werden zu können.
Statistische Zuverlässigkeit: Konfidenzintervalle
In der Korpuslinguistik werden anhand von Beobachtungen in einer Stichprobe, dem Korpus,
Aussagen über die Grundgesamtheit, aus der die Stichprobe stammt, also die untersuchte
Sprachdomäne, getroffen. Im Falle eines Neologismus im Neologismenwörterbuch dient
seine relative Häufigkeit im Zeitungskorpus als eine Schätzung seiner wahren relativen
Häufigkeit in der deutschen Allgemeinsprache oder zumindest in der allgemeinen
Zeitungssprache. Die Genauigkeit dieser Schätzung kann durch ein Konfidenzintervall
angegeben werden. Das Konfidenzintervall bezieht sich immer auf eine bestimmte, vorher
festgelegte Wahrscheinlichkeit, das Konfidenzniveau, welches in unserer Anwendung auf 95%
festgelegt ist. Das Konfidenzintervall wird dann anhand der beiden Parameter beobachtete
absolute Häufigkeit und Korpusgröße berechnet. In unseren Zeitverlaufsgrafiken
sind die Konfidenzintervalle durch einen Balken um den Wert der relativen Häufigkeiten
herum aufgetragen. 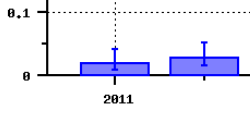
Abbildung: Ausschnitt der Zeitverlaufsgrafik für
Helikoptereltern
Beispielsweise lag die anhand des Zeitungskorpus
ermittelte relative Häufigkeit des Neologismus Helikoptereltern im Jahr 2011 bei 0,018 pMW. In
der zugehörigen Zeitverlaufsgrafik ist das berechnete Konfidenzintervall [0,008...0,040]
als Balken um den Wert 0.018 herum aufgetragen. Die Aussage ist: Mit einer Wahrscheinlichkeit
von 95% liegt die wahre relative Häufgkeit von Helikoptereltern in diesem Intervall. Ein
kleineres Konfidenzintervall zeigt also eine größere Genauigkeit des Schlusses
auf die gesamte Sprachdomäne an. Ein kleineres Jahreskorpus oder eine geringere absolute
Worthäufigkeit im Korpus bewirken ein größeres Konfidenzintervall.
Seitenanfang