| zeilenorientierte Eingabe → themenspezifische Fragestellungen |
Themenspezifische Fragestellungen und deren Lösung
Einleitung
Auf dieser Seite werden einfache bis komplexe sprachwissenschaftliche Fragestellungen aufgelistet, für die konkrete Suchanfragen oder Suchanfragmuster angegeben und erläutert werden. Durch Rückverweise auf die zugehörigen Seiten der (zeilenorientierten) Syntax kann die Funktionsweise der benutzten Operatoren parallel dazu erlernt werden.
- Für ein besseres Verständnis werden komplexe Suchanfragen nach und nach
aufgebaut und erläutert, wobei die Teilanfragen mit
Q1,Q2, etc. bezeichnet werden. Die vollständige Suchanfrage, wie sie auch von COSMAS II verstanden wird (dieQ1,Q2, etc. sind nicht Bestandteil der Suchanfrage-Syntax), ergibt sich aus dem Einsetzen vonQ1inQ2,Q2inQ3etc.
- Eine kochbuchartig aufgebaute Sammlung einfacherer Problemstellungen und deren Lösung ist ebenfalls verfügbar.
- Eine generelle Bemerkung zu regulären Ausdrücken in COSMAS II-Suchanfragen finden Sie hier.
Übersicht
- Wörter und Sonderzeichen:
- Suchanfragen, die die Satzstruktur betreffen:
- Suchanfragen, die den ling. Satzbau betreffen:
- Suche nach dem ersten Komma eines Satzes
- Suchen nach einem Komma in einem bestimmten Kontext
- Muster einer Suchanfrage für die indirekte Rede
- Muster einer Suchanfrage für die indir. Rede mit "dass+soll"
- Muster einer Suchanfrage für Verb + abgetrennte Verbpartikel ohne Reflexivpronomen
- Muster einer Suchanfrage für elliptische Sätze
- Muster einer Suchanfrage für die Ersetzung einer Komponente in Redewendungen
- Muster einer Suchanfrage für den Adhortativ - neu
- Suchanfragen, die die formale Textstruktur betreffen:
- Erweitern/Verändern des Suchbereichs eines Ergebnisses:
- Suchanfragen mit morphosyntaktischen Annotationen (Wortklassen):
- Suchanfragen für die Kookkurrenzanalyse:
| zeilenorientierte Eingabe → themenspezifische Fragestellungen → Wörter und Sonderzeichen |
Suchanfragen für Wörter mit/ohne Bindestrich
1. Suchanfragen nach dem Muster "Bauern- und Landfrauenverein"
Vorbemerkung
Der Tokenisierer von COSMAS II behandelt den Bindestrich wie Satzzeichen und Sonderzeichen an den Wortgrenzen: sie werden für die Suche am Ende des Wortes gelöscht, können dafür einzeln gesucht werden. Sucht man beispielsweise nach Bauern, findet man auf diese Weise »Bauern«, »Bauern-«, »Bauern,«, etc. Außerdem können durch die Suche nach dem Zeichen »-« alle Wörter mit Bindestrich am Wortende gefunden werden.
Das allgemeine Muster, um die obige Bindestrichform der Art X- und Y zu suchen, besteht somit aus den beiden Invarianten: dem Bindestrich und dem Wort "und".
Formulierung
| Q1 = - /+w1:1,s0 "und" |
Bemerkungen
- der Suchbegriff »-« findet in COSMAS II Wörter mit einem Bindestrich am Wortende.
- der Abstand zwischen dem Bindestrichwort und dem "und" wird mit /+w1:1,s0 so angegeben, dass sich die beiden gesuchten Wörter genau folgen und innerhalb eines Satzes befinden müssen.
- das Wort und muss zwischen Hochkommata geschrieben werden, ansonsten wird es von COSMAS II als Operator UND verstanden.
Auszüge aus einem derart gewonnenen KWIC
-
Appenzeller- und Schweizer-Huhn-Züchter-Clubs
Wahl- und Stimmrecht.
Gesangs- und Instrumental-Mediationen
Plan- und Baugesuchsunterlagen
2. Bestimmte Realisierungen der Bindestrichform
Soll das Suchmuster X- und Y mit einem konkreten Wort für X oder Y eingegrenzt werden, kann am Beispiel von Bauern- und Landfrauenverein die folgende Suchanfrage formuliert werden:
| Q2 = (- /w0 &Bauer) /+w1:1,s0 "und" /+w1:1,s0 &Landfrauenverein |
Erläuterungen
- die Suchbegriffe - und &Bauer werden mittels /w0 miteinander kombiniert und ergeben die Liste der Bindestrichwortformen von Bauer.
- Für &Landfrauenverein schalten Sie in den Lemmatisierungsoptionen mindestens die Komposita ein.
Man kann noch einen Schritt weitergehen und statt Landfrauenverein ganz allgemein die Komposita von Verein suchen:
| Q3 = (- /w0 &Bauer) /+w1:1,s0 "und" /+w1:1,s0 &Verein |
Dies ergibt folgende Belege:
Auszüge aus den Ergebnissen der Suche Q3
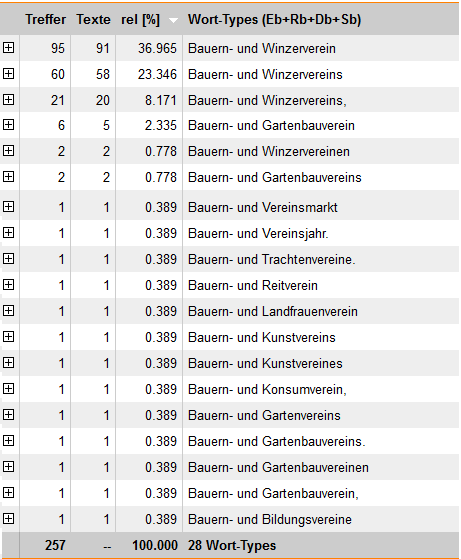
Ergebnisse (Auszüge) zu Bauern- und &Verein in Archiv W
3. Ausschließen der Bindestrichform
Die unter 1. formulierte Bindestrichform kann genauso auch als unerwünschter
Beleg auftreten.
Sucht man zum Beispiel nach den Genitivformen von Bauer unter Verwendung
der folgenden Suchanfrage,
| Q4 = (des oder eines) /+w2 (Bauern oder Bauers oder Bauerns) |
so erhält man auszugsweise folgende unerwünschte Belege mit Bindestrichform:
-
des Bauern- und Winzerverbandes
Bauern- und des Weihnachtsmarktes
verbesserte Formulierung
Hierzu muss man von den Formen Bauern, Bauers und Bauerns die Bindestrichform mittels des Ausschießungsoperators %w0 ausschließen.
| Q5 = (des oder eines) /+w2 ((Bauern oder Bauers oder Bauerns) %w0 -) |
Suche an einer bestimmten Satzposition
Beispiel 1
Hierfür kann der Operator
#IN
verwendet werden. Mit seinem Argument
<I> läßt
sich angeben,
an welcher Stelle von Y der Suchbegriff X gesucht bzw. nicht gesucht
werden soll. Wie in der folgenden Tabelle veranschaulicht wird, schließen
sich die aus dem I-Wert L, R, F
und N erhaltenen Ergebnisse gegenseitig aus.
| Suchanfrage | Erläuterung | Häufigkeit1 |
|---|---|---|
wegen #IN(L) <s> |
wegen am Satzanfang | 202.206 |
wegen #IN(R) <s> |
wegen am Satzende | 11.095 |
wegen #IN(F) <s> |
wegen von Satzanfang bis Satzende | 50 |
wegen #IN(N) <s> |
wegen weder am Satzanfang noch -ende | 1.455.943 |
| Summe von L, R, F und N | 1.669.294 | |
wegen #IN <s> |
keine Spezifizierung, d.h. alle Fälle zusammen | 1.669.294 |
Die Tabelle zeigt die Ergebnisse der Suche nach wegen (groß- oder kleingeschrieben, keine Unterscheidung der Wortklassen), in Sätzen (<s>) des gesamten Archivs für die Optionen L, R, F und N. Häufigkeit von wegen: 1.669.349. Anzahl Sätze: 222.564.359.
Diese 4 Optionen schließen sich gegenseitig aus. Ein und der gleiche Treffer kann
z.B. nicht durch die Optionen L und F erhalten werden.
Zusammengefasst werden diese Optionen bei der Verwendung von
#IN ohne Option
(letzte Suchanfrage in der obigen Tabelle),
die die gleichen Treffer liefert wie die vier Optionen zusammen.
Die Vorgabe F ist in diesem Fall insofern exotisch, als dass sie den Suchbegriff nur in Sätzen der Länge 1 finden kann, bei denen Satzanfang und -ende identisch sind.
Bemerkungen
Analog lässt sich z.B. in Absätzen (<p>), Überschriften (<ü>) und beliebigen anderen Textmarkierungen recherchieren.
Da wegen eigentlich 1.669.349 mal im Archiv belegt ist, wurden durch die obigen Suchanfragen 1.669.349 - 1.669.294 = 55 Fälle nicht abgedeckt. Es handelt sich um Fälle, bei denen wegen außerhalb einer <s> ... </s> Markierung (in einem <byline> außerhalb des Textbody) gefunden wurde. Diese Fälle lassen sich mit folgender Suchanfrage unter Verwendung der Ausschließungsoption % erfragen:
| Q1 = wegen #IN(%) <s> |
Q1 liefert tatsächlich die restlichen 55 Treffer.
Beispiel 2
In diesem Beispiel wird nach Sätzen gesucht, die mit unter und Hausarrest beginnen und enden. Zu diesem Zweck wird die Option F verwendet.
Q2 = unter /+s0 Hausarrest
|
Die Optionen FE und FI sind zwei Unteroptionen von F, die eine weitere Verfeinerung der Suchanfrage gestatten. Dabei verteilen sich alle Treffer von F entweder auf FE oder auf FI, wie aus der nächsten Tabelle ersichtlich ist:
| Suchanfrage | Erläuterung | Häufigkeit1 |
|---|---|---|
Q1 #IN(F) <s> |
wegen am Satzanfang und Hausarrest am Satzende | 13 |
Q1 #IN(FE) <s> |
wie F, aber keine anderen Wörter im Satz | 11 |
Q1 #IN(FI) <s> |
wie F, aber mindestens ein weiteres Wort im Satz | 2 |
Textbeispiel für einen Treffer mit FE
»Unter Hausarrest.«
Textbeispiel für einen Treffer mit FI
»Unter derselben Anklage sitzt der frühere Juntachef Jorge Videla seit fünf Monaten im Hausarrest.«
1 : im Archiv W - Achiv der geschriebenen Korpora, Stand August 2009.
Suche in Sätzen einer bestimmten Länge
Beispiel 1: Erfragen von Sätzen einer bestimmte Länge
Mit der hier vorgestellten Suchanfrage können Sätze einer bestimmten Länge
ausgewählt werden. Die Operatoren #BEG
und #END sowie
der Satz-Suchbebriff <s> werden hierzu wie folgt benötigt:
Selektieren von Sätzen bis zu einer Länge von 5 Wörtern
| Q1a = #BEG(<s>) /5w,s0 #END(<s>) |
Hierzu werden der Satzanfang #BEG(<s>) (= das 1. Wort im Satz)
und das Satzende #END(<s>) (= das letzte Wort im Satz)
in dem gewünschten Abstand von bis zu 5 Wörtern (/5w) und im selben Satz (s0)
voneinander gewählt. Liegen Anfangs- und Endwort max. 5 Wörter
auseinander, so auch die Satzlänge.
Selektieren von Sätzen mit einer Länge von genau 5 Wörtern
| Q1b = #BEG(<s>) /5:5w,s0 #END(<s>) |
Diese Suchanfrage liefert Sätze mit einer exakten Länge von 5 Wörtern zurück.
Selektieren von Sätzen mit einer Länge von über 5 Wörtern
| Q1c = #BEG(<s>) /6:100w,s0 #END(<s>) |
Diese Anfrage liefert Sätze mit einer min. Länge von 6 Wörtern zurück.
Der Bereich 6:100w (min. 6 bis max. 100) ist ein
Kunstgriff: da die Angabe eines Maximalwertes erforderlich ist, wird hier ein
beliebige hoher und angemessener Wert eingesetzt.
Bemerkung zum Textbereich solcher Ergebnisse
Die auf diese Weise ausgewählten Sätze werden,wie man im KWIC sehen kann, intern als Ergebnisse von Wortpaaren verwaltet, deren Textbereich jeweils das erste und letzte Wort dieser Sätze sind. Ein Beispiel für einen solchen Textbereich wäre:
»Aufrecht gaben sie ihr Leben.«
Die Verteilung der auf diese Art ausgewählten Sätzen kann mit der Ergebnisansicht statistische KWIC-Auswertung angezeigt werden.
Beispiel 2: Suchen von Suchbegriffen in Sätzen bestimmter Länge
Soll nun in den in Beispiele 1 ausgewählten Sätzen gesucht werden, muss
bedacht werden, dass nicht nur im roten Bereich gesucht wird (siehe Beispiel oben).
Der Textbereich muss auf die ganzen Sätze ausgehnt werden.
Dies wird beim Einsatz von Operator
#IN(all) mit Option all
gewährleistet.
Nehmen wir an, wir suchen nach der Kombination der beiden Wörter geben und Leben in Sätzen der Länge 10 oder weniger. Was passiert, wenn man den Textbereich aus Beispiel 1 unverändert belässt:
Suchanfrage mit dem falschen Textbereich
| Q2a = (&geben /+s0 Leben) #IN (#BEG(<s>) /10w,s0 #END(<s>)) |
Die Suchanfrage mit #IN ohne Option ergibt nicht die erhofften Treffer, weil die Suchbegriffe &geben und Leben nur im roten Textbereich gesucht werden und nicht in den ganzen Sätzen.
Suchanfrage mit dem korrekten Textbereich
In der korrigierten Version wird #IN(all) eingesetzt. Die Option
all hat die Wirkung, dass der Textbereich auf alle Wörter der Sätze
erweitert wird:
»Aufrecht gaben sie ihr Leben.«
Die korrekte Suchanfrage lautet:
| Q2b = (&geben /+s0 Leben) #IN(all) (#BEG(<s>) /10w,s0 #END(<s>)) |
und findet unter anderem folgenden Treffer (Beispiel):
»Aufrecht gaben sie ihr Leben.«
Beispiel 3: Suchen an bestimmter Position von Sätzen bestimmter Länge
Der Operator #IN() erlaubt uns dank weiterer Optionen, zusäztlich
an bestimmten Position in den ausgewählten Sätzen zu recherchieren.
Dazu ein Beispiel:
Suchen am Anfang von Sätzen, deren Länge maximal 10 ist
| Q3 = (&geben /+s0 Leben) #IN(all,L) (#BEG(<s>) /10w,s0 #END(<s>)) |
Mit der Option L wird am Anfang (L = links) von Sätzen gesucht, wie das folgende Beispiel bezeugt:
»Gibt es ein Leben nach dem Match?«
Weitere Optionen für #IN() finden Sie unter der Beschreibung von <I>.
Suchanfrage nach dem ersten Komma eines Satzes
Problemstellung
Gewünscht wird die Liste aller nach dem Satzanfang als erste auftretenden Kommata. Dort, wo ein Satz mehrere Kommata beinhaltet, soll also nur das erste zurückgeliefert werden.
Eine solche Suchanfrage würde man gerne mit Hilfe von regulären Ausdrücken formulieren. Da COSMAS II keine regulären Ausdrücke anbietet, muss die hier vorgeschlagene Formulierung gewählt werden, die sich auf Satzenden stützt.
Beispiel
"So ging es nicht um eine konstruktive Kritik, wie mit dem Erbe des parteiischen Journalismus' umzugehen sei, sondern allein um eine Rückschau aus der Sicht der Sieger."
In diesem Beispiel soll das Komma nach Kritik zurückgeliefert werden.
Vorgehen
Man sucht nach allen Satzenden, kombiniert sie mit der Gruppe der im selben Satz gefundenen Kommata und wählt aus jeder Gruppe das am weitesten links stehende aus.
Formulierung
| Q1 = <se> |
Der Suchbegriff <se> sucht direkt nach den Satzenden und liefert davon das letzte Wort. In obigem Beispiel:
»... aus der Sicht der Sieger.«
| Q2 = , /+s0 Q1 |
Man sucht über den 0-Satzabstand alle Kommata, die in einem gleichen Satz vorkommen
(+s0)
und fasst sie zu einer Gruppe zusammen (max).
Der Trick hierbei besteht darin, alle Kommata im gleichen Satz
wie ein Satzende zu suchen,
damit man sie überhaupt zu einer Gruppe zusammenfassen kann.
Im KWIC erscheint das obige Beispiel wie folgt:
»So ging es nicht um eine konstruktive Kritik, wie mit dem Erbe des parteiischen Journalismus' umzugehen sei, sondern allein um eine Rückschau aus der Sicht der Sieger.«
| Q3 = #BEG(Q2) |
Aus der Gruppe der Kommata eines Satzes wählt man das am weistesten links stehende aus. Das funktioniert natürlich auch für Sätze mit nur einem Komma.
Die komplette Formulierung, nach Ersetzung der Q2 und Q1, lautet:
| Q3 = #BEG( , /+s0,max <se> ) |
Im KWIC erscheint obiges Beispiel wie folgt:
»... nicht um eine konstruktive Kritik, wie mit dem ... «
Suchanfrage nach einem Komma in einem bestimmten Kontext
Problemstellung
Gesucht werden die Textstellen, bei denen das erste Komma eines Satzes folgende Bedingungen erfüllt: kein Verb unmittelbar davor und kein Relativpronomen unmittelbar danach.
Vorgehen
Man sucht wie im Beispiel des ersten Kommas
im Satz nach der Liste aller Kommata, die als erste in einem Satz
vorkommen und schließt nacheinander diejenigen aus, in deren Umgebung z.B.
unerwünschte Wortklassen auftreten. Dazu benötigt man den
ausschließenden Abstandsoperator %.
Formulierung
Zuerst suchen wir mit Suchanfrage Q1 nach dem ersten Komma eines
Satzes:
| Q1 = #BEG(, /+s0 <se>) |
In Q2 werden die in Q1 gefundenen Kommata ausgeschlossen (%), die
auf einem Verb folgen. Da ein solches Verb einen Wortabstand von 0 von dem gesuchten Komma hat,
wird es mit %w0 gefunden:
| Q2 = Q1 %w0 MORPH(VRB)) |
Ausnahme: im gegenwärtigen Archiv TAGGED muss an dieser Stelle der Abstand -1 stehen, weil infolge einer veralteten Kodierung das Komma als selbstständiges Textwort getrennt vom Vorwort kodiert wurde (Beispiel: "... wetten , dass ...").
Von den in Q2 gefundenen Kommata werden nun diejenigen ausgeschlossen (%), auf die unmittelbar (+w1:1) ein Relativpronomen folgt. Der Minimalwortabstand 1 (die 1 vor dem :) ist notwendig, um sicherzustellen, dass die Wortklasse des nächsten Wortes genommen wird.
| Q3 = Q2 %+w1:1 MORPH(PRN rel) |
Die vollständige Suchanfrage, durch Ersetzung von Q1 und Q2, lautet:
| Q3 = (#BEG(, /+s0 <se>) %w0 MORPH(VRB)) %+w1:1 MORPH(PRN rel) |
Verallgemeinerung
Will man in Q2 die Kommata ausschließen, bei denen in einem linken Kontext von 3 Wörtern ein Verb vorkommt, muss der Abstand so lauten:
%-w2, d.h. %-w0:2,
d.h. die Wörter an den Positionen 0, 1 und 2 im linken Kontext,
wobei dann tatsächlich
der maximale Abstand 2 das dritte Wort links vom Komma bezeichnet.
Muster einer Suchanfrage für die indirekte Rede
In den IDS-Korpora können Textstellen mit indirekter Rede nicht direkt abgefragt werden, da diese nicht annotiert ist. Vorgeschlagen wird hier ein Suchanfragemuster, bei dem ein Typus von indirekter Rede approximativ recherchiert werden kann. Dabei kann nicht ausgeschlossen werden, dass falsche Belege gefunden und korrekte Belege nicht gefunden werden.
Problemstellung
Es werden Belege von indirekter Rede gesucht, die folgendes Muster aufweisen:
"sagte" + Komma + "dass" + einige Wörter frei +
("habe" oder "hätte" oder "sei" oder "ist" oder "wäre")
wobei wir zwischen "dass" und dem Verb Satzzeichen wie Komma, Doppelpunkt, etc.
ausschließen wollen.
Für ein besseres Verständnis wird die gesamte Suchanfrage in Teilsuchanfragen (Q1 bis Q5),
die nacheinander ausgeführt werden können, aufgebaut.
Beispiel eines gewünschten Beleges
Eugster sagte, dass die Gemeinde keinen Zeitdruck habe.
Aufbau der Suchanfrage
| Q1 = sagte /w0 , |
| Q2 = Q1 /+w1 dass |
Mit Q2 erhalten wir die Einleitung der indirekten Rede.
| Q3 = #END(Q2) |
Mit Q3 behalten wir das Wort "dass" (das am weitesten
rechts in Q2 auftretende Wort) für die folgenden
Recherchen. Dies ist wichtig für Q5.
| Q4 = Q3 /+s0,min (habe hätte sei ist wäre) |
Mit Q4 schränken wir nun die Belege auf
Wortfolgen innerhalb eines Satzes, in denen links "dass" steht,
rechts eines der Wörter "habe", "hätte", etc... (alle gewünschten
Varianten können hintereinander ohne Operator oder geschrieben werden,
wenn die Option weggelassener Operator auf oder gesetzt ist).
Im Abstandsoperator wird außerdem das Schlüsselwort min spezifiziert. Das ist wichtig, damit ein Fall wie F1 als mehrere unabhängige Belege behandelt wird:
F1 = " ... sagte, dass er viele davon schon habe und, da sei er sich sicher, keines jemals gelesen habe."
Für F1 erzeugt Q4 durch Anwendung des Schlüsselwortes min
drei unabhängige Belege:
B1 = " ... sagte, dass er viele davon schon
habe ...."
B2 = " ... sagte, dass er viele davon schon habe und,
da sei ...."
B3 = " ... sagte, dass er viele davon schon habe und,
da sei er sich sicher, keines jemals gelesen habe."
Jeder dieser Belege wird einzeln in Q5 ausgewertet, wobei nur
Beleg B1 die Bedingung erfüllt.
Ohne Anwendung von min würde Q4 statt drei Belegen nur einen einzigen Beleg weiterreichen,
welcher von Q5 als ganzes herausgefiltert werden würde. Im Endeffekt hätten
wir einen korrekten Beleg ausgeschlossen.
| Q5 = Q4 %w0 , |
Mit Q5 werden nun alle bisherigen Belege ausgeschlossen, bei denen ein Komma
zwischen dass und dem Verb vorkommt (einschließlich dass und Verb).
Das Komma kann an dieser Stelle ersetzt werden durch eine Liste von Satzzeichen,
die man ausschließen möchte. Der Satzendepunkt braucht nicht in der Liste aufgenommen zu werden,
da in Q4 gewährleistet wird, dass alle Wörter eines Beleges innerhalb
eines Satzes gefunden werden.
Die gesamte Suchanfrage Q5 lautet also:
| Q5 = (#END((sagte /w0 ,) /+w1 dass) /+s0,min (habe hätte sei ist wäre)) %w0 , |
Einschränkung
Diese Suchanfrage hat eine Ungenauigkeit: Ein Beleg
wird in Q5 auch dann ausgeschlossen, wenn ein Komma genau hinter dem Verb ("hätte,", "habe,", etc.)
auftritt. Um dies zu verhindern, müssen wir auf eine Erweiterung der Suchmaschine warten.
Muster einer Suchanfrage für die indirekte Rede mit "dass + soll"
Problemstellung
Gewünscht sind Belege von indirekter Rede nach folgendem Muster:
Verb1 + , + dass ... + Verb2 + haben + soll
Dabei könnte Verb1 auch durch eine Liste von
passenden Verben wie behaupten, sagen, etc. ersetzt werden.
Die Suchanfrage muss so formuliert werden, dass alle Wörter im selben Satz
gesucht werden. Der Abstand zwischen der Konjunktion und Verb2
kann beliebig groß sein.
Beispiel eines gewünschten Belegs
Die Zeitschrift hatte fälschlicherweise behauptet, dass sich die Prinzessin ihren Adelstitel unredlich erworben haben soll.
Formulierung
| Q1 = MORPH(VRB) /+w0:1 , |
Q1 deckt den Hauptsatz ab. Auf das Verb soll
unmittelbar danach oder in einem Abstand von einem Wort
(+w0:1) ein Komma folgen.
| Q2 = (dass daß) /+s0 (MORPH(VRB) /+w1:1 (haben /+w1 (soll sollen))) |
Q2 deckt den Nebensatz mit der indirekten Rede ab:
die Konjunktion dass wird in der neuen und alten Rechtschreibung
angegeben. Im selben Satz (+s0) folgt die Verbgruppe mit
einem freien Verb gefolgt von haben und soll oder sollen,
den beiden möglichen Deklinationen von sollen an dieser Stelle.
Der Abstand +w1:1, d.h. mindestens und höchstens ein Wort
Abstand, zwischen dem Verb und haben ist wichtig, weil haben
selber auch ein Verb ist.
| Q3 = Q1 /+w1:1 Q2 |
Q3 verknüpft Haupt- und Nebensatz so, dass die
Konjunktion dass unmittelbar auf das Komma folgt
(+w1:1).
Die vollständige Suchanfrage, nach Ersetzung von Q1 und Q2, lautet:
| Q3 = (MORPH(VRB) /+w0:1 ,) /+w1:1 ((dass daß) /+s0 (MORPH(VRB) /+w1:1 (haben /+w1 (soll sollen)))) |
Muster einer Suchanfrage für "elliptische Sätze"
Problemstellung 1
Gewünscht sind Belege von elliptischen Sätzen ohne präpositionale Ergänzung. Als Beispiel suchen wir nach "ich freue mich.".
Ansatz: elliptischer Satz = ganzer Satz. D.h.:
ich (= Satzanfang) freue mich (= Satzende)
Beispiel eines gewünschten Belegs
Er stempelt und winkt mich durch. Ich freue mich. Aber Kahn tut auch mir leid.
Formulierung
| Q1 = (ich /w0 <sa>) /+w1 freue /+w1 (mich /w0 <se>) |
Q1 setzt die beiden Markierungen <sa> und <se> ein,
die für das 1. bzw. letzte Wort eines Satzes stehen. Dadurch werden alle ich
ausgewählt, die am Satzanfang stehen und alle mich, die am Satzende stehen.
Eine ähnliche Lösung ist die folgende:
| Q2 = ich:sa /+w1 freue /+w1 mich:se |
Q2 setzt direkt die Bedingung Satzanfang (:sa) und
Satzende (:se) ans Ende der gesuchten Wörter ich und mich ein.
Unterschiede zwischen beiden Suchanfragemuster
Beide Suchanfragemuster unterscheiden sich wie folgt:
| Suchanfrage | Anz. Treffer | Ausführungszeit | Satzgrenzen |
|---|---|---|---|
| Q1 | 118 | langsam | die Markierung <s> ... </s> |
| Q2 | 220 | schnell | die Markierung <s> ... </s> der Doppelpunkt |
Suchanfrage Q2 enthält die Belege von Q1 und zusätzlich Belege, bei denen der Tokenizer von COSMAS II bei einem Doppelpunkt, einem Ausrufezeichen, etc. eine zusätzliche Satzgrenze (ungeachtet des Inhalts) eingefügt hat.
Beispiele von Belegen, die nur von Q2 gefunden werden
Erste Reaktion: "Ich freue mich".
"Ich freue mich": ein Stück Nichtvergessensein.
«Ich freue mich!», ruft Schöneberger schon, als sie noch hinterm Vorhang steht...
Problemstellung 2
Die obige Problembestellung soll so erweitert werden, dass am Satzende ein freies Wort zugelassen wird.
Formulierung
| Q3 = ich:sa /+w1 freue /+w1 (mich /w1,s0 <se>) |
Q3 ist eine Mischlösung aus Q1 und Q2.
Um sicher zu sein, dass zwischen mich und dem letzten Wort des Satzes nicht
noch eine Satzgrenze verläuft, wird /+w1,s0 benutzt.
Beispiel eines Belegs für Q3
"Ich freue mich mordsmäßig.
Muster für die Ersetzungen einer Komponente in Redewendungen
Problemstellung
Gesucht werden für eine Komponente einer Redewendung deren Ersetzungen oder Varianten. Zum Beispiel für die Redewendung »die Letzen beißen die Hunde« wollen wir nach Ersetzungen für die Komponente »die Letzten« suchen.
Die Suchanfragen und Textbeispiele können mit dem CONNEXOR-Tagset im Archiv TAGGED-C nachvollzogen werden.
Muster mit Wortlaut
|
Q1a = beißen die Hunde Q1b = beißen /+w1,s0 die /+w1,s0 Hunde |
Beispiel
Den Letzten und den Kleinsten beißen die Hunde
Mit Q1 werden schon erste interessante Belege gefunden, bei denen »beißen
die Hunde« fest vorgegeben ist. Bei Q1b wird der Wortabstand 1
explizit angegeben; der Wortabstand ist, wie in Q1a implizit auch 1,
wenn die Suchoption "weggelassener Verknüpfungsoperator" auf "Wortabstand" gesetzt ist.
| Q2 = (beißen oder beissen) die Hunde |
Beispiel
Die letzten Prüflinge beissen die Hunde
Mit der Variante beissen werden zusätzlich auch Belege z.B. in Schweizer Zeitungen gefunden.
Muster mit Varianten von beißen
Sollen Varianten von beißen gesucht werden, z.B. beißen im Singular, hilft folgendes Muster weiter. Dabei ist zu beachten, dass Hund und sein Artikel auch im Singular gefunden werden müssen. Deshalb wird in der folgenden Suchanfrage der Artikel zwischen beißen und Hund weggelassen (Wortabstand 2!) und Hund über seine Grundform gesucht:
| Q3 = &beißen /+w2,s0 &Hund |
Wie zu erwarten war, findet sich unter den Belegen im Singular keine Variante unserer Redewendung.
Muster mit Wortklassen für die ersetzte Komponente
| Q4 = (MORPH(DET) /+w1:1,s0 (MORPH(A) oder MORPH(N))) /+w1:1,s0 (beißen /+w1,s0 die /+w1,s0 &Hunde) |
Für die Ersetzung wurde hier das syntaktische Muster 'Artikel (Adjektiv oder Nomen)' gewählt. Im Falle von »den Letzten« tritt die Situation ein, dass Letzten vom Tagger als Adjektiv annotiert wird.
Beispiel
Den<DET @PREMOD> Letzten<A @NH> beißen<V IND PRES @MAIN> die<DET @PREMOD> Hunde.<N PL @NH>
Suchanfragen in Überschriften
Verfügbare Überschriften in den IDS-Korpora
In den CES-kodierten IDS-Korpora sind folgenden Arten von Überschriften kodiert, die in Suchanfragen benutzt werden können. Wir geben hier zur Veranschaulichung eine Übersicht mit Zahlen für das Archiv W - Archiv der geschriebenen Korpora mit einem Umfang von 10 Mio. Texten, Stand Juli 2009, wieder:
| Art der Überschrift | Kodierung | Suchbegriff | Anzahl |
|---|---|---|---|
| Dachzeile | <HEAD TYPE=TOP> | <üd> | 2.196.162 |
| Hauptüberschrift | <HEAD TYPE=MAIN> | <üh> | 10,655.085 |
| Unterüberschrift | <HEAD TYPE=SUB> | <üu> | 3.602.567 |
| Zwischenüberschrift | <HEAD TYPE=CROSS> | <üz> | 4.841.568 |
| Restkategorie | <HEAD TYPE=UNSPECIFIED> | <ür> | 367.687 |
| alle Überschriften | <HEAD> | <ü> | 21.663.069 |
Die Großschreibung bei der Kodierung ist zu beachten.
Textbeispiel mit Textauszeichnungen für Überschriften
<div>
<head type="top">
<s>Innenstadt: Ehren- und Offiziersabend des Mannheimer
Traditionscorps mit Büttenreden und Gardetanz</s>
</head>
<head type="main">
<s>Führungswechsel kündigt sich an</s>
</head>
<p>Seit 42 Jahren ist ...</p>
</div>
Beispiele
Beispiel 1: Spezifikation von Überschriften in Suchanfragen
| <üd> |
Erfragen der Dachzeilen in den Zeitungstexten der IDS-Korpora. Siehe Textbeispiel oben.
Über die Suchbegriffe <üh>, <üu>, <üz;gt; etc. lassen sich analog die Haupt-, Unter- und Zwischenüberschriften erfragen.
| <üd> oder <üh> |
In dieser Anfrage werden Dach- oder Hauptüberschriften erfragt.
| <ü dh> |
Diese Anfrage ist eine Kurzform für die vorangehende ODER-Suche.
| <ü -uzr> |
In dieser ausschließenden Anfrage werden alle Überschriften gesucht, die keine Unter-, Zwischen- und unspezifizierte Überschriften sind. Gemäß unserer Übersichtstabelle müssten dabei wieder die Dach- und Hauptüberschriften herauskommen.
Beispiel 2: Suchen von Suchbegriffen innerhalb von Überschriften
| wegen #IN <üd> |
Damit wird wegen an einer beliebigen Stelle innerhalb einer Dachüberschrift gesucht.
Beispiel 3: Suchen von Suchbegriffen an einer bestimmten Position von Überschriften
| wegen #IN(L) <üd> |
Damit wird wegen am Anfang einer Dachüberschrift
(Wert L im Argument <I>
von Operator IN) gesucht.
Analog lassen sich Suchbegriffe am Ende (Wert R) oder streng innerhalb (weder am Anfang noch am Ende, Wert N) von Überschriften erfragen.
| Terror #IN(F) <üd> |
Mit dem Wert F wird ein Spezialfall erfragt, da durch diese Option Anfang und Ende der Überschrift mit dem Suchbegriff Terror zusammenfallen müssen. Die Ergebnisse sind 1-Wort-Dachüberschriften, die nur aus dem gesuchten Wort bestehen.
- Die Optionswerte L, R, F und N schließen sich gegenseitig aus. Ein Suchbegriff, der mit F gefunden wird, wird mit L nicht gefunden und umgekehrt.
Suchanfragen, die Überschriften ausschließen
Beispiele
Beispiel 1: Ausschließen von Überschriften aus den Ergebnissen
| wegen #IN(%) <ü> |
Mit der Ausschließungsoption im Argument
<I>
des Operators #IN
lassen sich wie in diesem Fall alle Überschriften aus den Ergebnissen
des Suchbegriffes wegen ausschließen.
Suchanfragen in mehreren Textbereichen
Beispiel 1: Suchanfragen in mehreren Textbereichen
| <üd> oder #ELEM(BYLINE) |
Erfragen von Dachzeilen und Byline-Zeilen.
Da es im Gegensatz zu den Überschriften (hier <üd>) nicht für alle CES-Textstrukturauszeichnungen ein suchbares Kürzel gibt, muss auf den #ELEM-Operatoren zurückgegriffen werden, der die Eingabe einer beliebigen CES-Auszeichnung erlaubt.
Was steht an den Satzenden eines Ergebnisses?
Wir gehen beispielsweise von einer Abstandsuche innerhalb eines Satzes aus und wollen
erfragen, was am Ende solcher Sätze steht. Wir suchen z.B. wie
in Q1 nach den Begriffen
Polizei und Demonstration:
| Q1 = &Polizei /s0 &Demonstration |
Um das Ergebnis von Q1 auf Satzebene auswerten zu können,
muss man den Ergebnisbereich von Q1
auf den ganzen Satz ausdehnen.
Beispiel eines Ergebnisbereichs von Q1:
»... Polizei ... Demonstration ...«
Nun folgt die Bereichserweiterung mit dem Überlappungs-Operator
#OV (engl. overlapps):
| Q2 = Q1 #OV <s> |
Dieser nimmt die Treffer von Q1 und kombiniert
sie mit den Sätzen des Archivs.
Dort wo sich ein Treffer von Q1 und ein Satz überlappen,
wird die Summe ihrer Bereiche übernommen.
Da der Ergebnisbereich von Q1 kleiner ist als der
eines Satzes, geht er in den Satzbereich auf.
Beispiel eines Ergebnisbereichs von Q2:
»Draußen kann die Polizei die unangemeldete Demonstration auflösen.«
Da der Ergebnisbereich von Q1
auf den ganzen Satz erweitert wurde, ist es nun möglich, mit z.B. Operator
#END
die Satzenden von Q1 zu betrachten
und sogar im KWIC alphabetisch sortieren zu lassen.
| Q3 = #END(Q2) |
Das Ergebnis von Q3 sind die Satzenden der Sätze, in denen Polizei und Demonstration
vorkommt. Für obiges Beispiel wäre dies:
»... auflösen.«
Die vollständige Suchanfrage, nach Ersetzung von Q1 und Q2, lautet:
| Q3 = #END((&Polizei /s0 &Demonstranten) #OV <s>) |
Desgleichen kann mit Operator
#BEG
erreicht werden, um den Satzanfang einer Suchanfrage zu betrachten.
Wie formuliere ich eine Überlappung von Textbereichen?
Wir wollen zu diesem Thema präsentieren, wie man mit den Operatoren #OV und /w0 Überlappungen von Textbereichen formulieren kann und welche Unterschiede zwischen diesen Operatoren bestehen.
1. Überlappungen mit #OV und #ALL
Ein Beispiel: wir möchten eine Sequenz von 2 Verben und eine Sequenz von 2 Nomen untersuchen, wenn sie sich überlappen. Jede der beiden Sequenzen läßt einen Abstand von mehreren Wörtern zwischen den Verben bzw. den Nomen zu. Ein erster Ansatz könnte wie folgt aussehen:
| Q1 = (MORPH(V) /+w1:3,s0 MORPH(V)) #OV (MORPH(N) /+w1:3,s0 MORPH(N)) |
Wir stossen auf ein erstes Problem: Da ein Verb kein Nomen ist und umgekehrt, haben die beiden zu kombinierenden Sequenzen (in der Folge auch Bereiche genannt) kein gemeinsames Wort. Da aber #OV so definiert ist, dass er eine Überlappung nur über gemeinsame Textstellen überprüft, liefert Q1 keine Treffer, so auch den folgenden erhofften Textausschnitt nicht:
»Der vom Helmstedter/N Lauftreff/N veranstaltete/V Silvesterlauf/N erfreut/V sich weiter großer Beliebtheit.«1
Um #OV in diesem Fall einsetzen zu können, muss die Suchanfrage wie in Q2 durch Hinzunahme des Operators #AlL formuliert werden:
| Q2 = #ALL(MORPH(V) /+w1:3,s0 MORPH(V)) #OV #ALL(MORPH(N) /+w1:3,s0 MORPH(N)) |
Durch den Einsatz von #ALL erhält #OV die Textbereiche »Helmstedter Laufsteg veranstaltet Silvesterlauf« und »veranstaltete Silversterlauf erfreut« und erkennt, dass beide Sequenzen sich überlappen. Nun erhält man den gewünschten Treffer:
»Der vom Helmstedter/N Lauftreff/N veranstaltete/V Silvesterlauf/N erfreut/V sich weiter großer Beliebtheit.«1
Der Nachteil mit dem Operator #ALL besteht darin, dass nicht nur die ursprünglich gesuchten Verben und Nomen hervorgehoben werden, sondern alle Wörter innerhalb der beiden Sequenzen. Im nächsten Textauszug sind die unerwünscht hervorgehobenen Wörter "vorher" und "damit" mit der Farbe ihrer zugehörigen Sequenz ebenfalls markiert:
»Schon stunden/N vorher hatten/V Arbeiter/V damit begonnen/V, in der Donaulände, ... .«1
Im nächsten Abschnitt zeigen wird, wie der Operator /w0 dieses Problem löst.
2. Überlappungen mit /w0
Eine Alternative zu #OV und #AlL bietet der Null-Wortabstand /w0, der einfacher zu handhaben ist und Überlappungen von Textbereichen erkennt, die keine gemeinsamen Wörter haben.
| Q3 = (MORPH(V) /+w1:3,s0 MORPH(V)) /w0 (MORPH(N) /+w1:3,s0 MORPH(N)) |
2.a Hervorheben der gesuchten Wörter
Hinzu kommt, dass COSMAS II nun in der Lage, nur die gesuchten bzw. gefundenen Wörter (die Verben und Nomen in unserem Beispiel) anzuzeigen:
»Schon stunden/N vorher hatten/V Arbeiter/V damit begonnen/V, in der Donaulände, ... .«1
2.b Minimalgruppen
Suchanfrage Q3 liefert korrekterweise auch solche Treffer, die auf den ersten Blick falsch zu sein scheinen:
»Nun ja, und ich sollte/V das Tigerfell/N geben/V, sollte/V Noahs/N Tritte/N kassieren/V und gleich zu Beginn des neuen Jahres am Boden liegen... .«
Ein solcher Treffer entsteht dann, wenn mehrere Sequenzen von Verben und Nomen sich gemäß der Suchanfrage Q3 kombinieren lassen. COSMAS II fasst sie dann gemäß der Default-Einstellung maximale Gruppenbildung korrekterweise zu 1 Treffer zusammen. In unserem Fall kommt ein solcher Treffer durch das Zusammenfassen der folgenden Sequenzen zusammen:
Sequenz »sollte das Tigerfell geben« überlappt »Tigerfell geben, sollte Noahs« überlappt »sollte Noahs Tritte kassieren« überlappt »Noahs Tritte«.
Will man dies verhindern, muss man in Q3 die minimale Gruppenbildung mittels »,min« angeben, und zwar für alle 3 Abstandsoperatoren:
| Q4 = (MORPH(V) /+w1:3,s0,min MORPH(V)) /w0,min (MORPH(N) /+w1:3,s0,min MORPH(N)) |
Suchanfrage Q4 erzeugt nun mehr Treffer bzw. KWIC-Zeilen, weil die gefundenen Sequenzen nicht mehr maximal zusammengefasst werden. Unser obiges Beispiel zerfällt in 4 Treffer:
»Nun ja, und ich sollte/V das Tigerfell/N geben/V, sollte Noahs/N Tritte kassieren und gleich zu Beginn ... .«
»Nun ja, und ich sollte das Tigerfell/N geben/V, sollte/V Noahs/N Tritte kassieren und gleich zu Beginn ... .«
»Nun ja, und ich sollte das Tigerfell/N geben, sollte/V Noahs/N Tritte kassieren/V und gleich zu Beginn ... .«
»Nun ja, und ich sollte das Tigerfell geben, sollte/V Noahs/N Tritte/N kassieren/V und gleich zu Beginn ... .«
1: Die Unterscheidung der beiden Sequenzen mit blau und rot, die hier zur besseren Veranschaulichung eingesetzt wird, kann von COSMAS II selber nicht vorgenommen werden.
Die adjektivische Konstruktion »nicht ... un-ADJ«
Das vorliegende Beispiel zeigt zugleich Anwendungsfälle der folgenden Ergebnispräsentationen:
Die grundlegende Suchanfrage
Wir interessieren uns für Adjektive mit Präfix un-, die mit dem Adverb nicht gebildet werden, also z.B. nicht von ungefähr, nicht eindeutig, etc.
Die Suchanfrage wird in einem morpho-syntaktisch annotierten Archiv wie TAGGED-C durchgeführt. Zwischen nicht und dem Adjektiv wollen wir maximal 3 Wörter zulassen. Die Suchanfrage läßt sich wie folgt formulieren, wobei "nicht" zwischen Hochkommata geschrieben werden muss, wenn es als Suchbegriff und nicht als Operator verstanden werden soll:
| "nicht" /+w1:4,s0 (MORPH(A) /w0 &un-) |
Die Grundform aller Wörter mit Präfix un wird mit &un- formuliert, außerdem muss die Lemmatisierungsoption sonstige Wortbildungsformen eingeschaltet werden.
Der Ausdruck (MORPH(A) /w0 &un-) schließlich findet alle Adjektive mit
Präfix un.
Das Ergebnis zählt 103.000 adjektivische Konstruktionen (KWIC-Zeilen), die im folgenden KWIC auszugsweise dargestellt werden:
|
Abb. 1: KWIC-Ausschnitt für Suchanfrage "nicht" /+w1:4,s0 (MORPH(A) /w0 &un-) |

Die Liste der gesuchten un-Adjektive
Möchte man nun die Adjektive sortieren und nach Wort-Types zusammenfassen, so
geht man wie folgt vor: Die obige Suchanfrage wird so erweitert, dass die Treffer im KWIC
nur noch aus dem Adjektiv bestehen. Dass das Adjektiv in den gefundenen Konstruktionen
immer das letzte Trefferwort ist, erreichen wir, indem wir den Operator
#END (bzw. #RECHTS) auf die obige Suchanfrage ansetzen
mit der Auswirkung, dass die Referenz auf das letzte Wort verschoben wird:
| #END( "nicht" /+w1:4,s0 (MORPH(A) /w0 &un-) ) |
Nun liefert das neue KWIC nur noch die gefundenen Adjektive auf:
|
Abb 2.: KWIC-Ausschnitt für Suchanfrage "#END(nicht" /+w1:4,s0 (MORPH(A) /w0 &un-)) |

Die Ansicht nach Wort-Types
Nun können die Adjektive mittels der Ansicht nach Wort-Types zusammengefasst und nach ihrer relativen Häufigkeit sortiert werden. In der folgenden Abbildung sind die häufigsten zu sehen:
|
Abb 3.: Ansicht nach Wort-Types für "#END(nicht" /+w1:4,s0 (MORPH(A) /w0 &un-)) |
![[Ansicht nach Wort-Types]](WTypes_KWIC_Ansicht.jpg)
Die Wörter innerhalb von »nicht ... un-ADJ«
Als nächstes könnte man ähnlich verfahren, um sich die häufigsten Wörter zwischen nicht und den Adjektiven auf un- anzeigen zu lassen. Die obige Suchanfrage wird zu diesem Zweck wie folgt angepasst:
| #NHIT( "nicht" /+w2:4,s0 (MORPH(A) /w0 &un-) ) |
In diesem Fall wird der Operator #NHIT eingesetzt, weil er die
Referenz auf die Wörter zwischen den Treffern setzt, die in der Wort-Type-Ansicht
zusammengefasst werden sollen. Außerdem wird der minimale Abstand zwischen
nicht und dem Adjektiv auf 2 gesetzt, um die Fälle auszuschließen, bei denen
das Adjektiv unmittelbar auf nicht folgt.
Von den obigen 103.000 Treffer werden durch die neue Suchanfrage 31.474 KWIC-Zeilen ausgewählt. Diese wiederum lassen sich in der Ansicht nach Wort-Types auf 10.413 Einzelwörter oder Wortkombinationen zusammenfassen. Die häufigsten davon werden in der nächsten Abbildung gezeigt:
|
Abb 4.: Ansicht nach Wort-Types für die häufigsten Wörter zwischen 'nicht'
und dem Adjektiv, |
![[die häugisten Wort-Types zwischen <i>nicht</i> und den Adjektiven]](WTypes_KWIC_NHIT.jpg)
Aus der Tabelle kann man somit die in den IDS-Korpora häufigsten Einzelwörter und Wortkombinationen, die in der adjektivischen Konstruktionen nicht ... un-ADJ auftreten, ablesen. Zum Beispiel:
| nicht ganz un-ADJ | 11,8% | |
| nicht mehr un-ADJ | 5,6% | |
| ... | ... | |
| nicht mehr so un-ADJ | 0,689% |
Die Konstruktion »nicht … un-ADJ« für ausgewählte Adjektive
Interessiert man sich für die adjektivischen Konstruktion eines bestimmten Adjektivs, z.B. für nicht … ...unbedingt, so kann man mit folgender Suchanfrage arbeiten:
| #NHIT( "nicht" /+w4,s0 (MORPH(A) /w0 unbedingt) ) |
Die Ansicht nach Wort-Types, angewendet auf das auf diese Weise erzielte Ergebnis, liefert die Einzelwörter und Wortgruppen, die in dieser Konstruktion auftreten.
Die Größe der Konstruktion »nicht … un-ADJ« für ausgewählte Adjektive
Bleiben wir bei unserem Adjektiv unbedingt. Wir möchten wissen, wie groß die Konstruktion nicht … unbedingt in den IDS-Korpora ist. Dazu formulieren wir folgende Suchanfrage:
| "nicht" /+w4,s0 (MORPH(A) /w0 unbedingt) ) |
Mittels der Ergebnisauswertung stat. KWIC-Auswertung erfahren wir folgendes:
|
Abb 5.: statistische KWIC-Auswertung von »nicht … unbedingt« |
![[stat. KWIC-Auswertung von <i>nicht … unbedingt</i>]](KWIC-Auswertung_nicht_unbedingt.jpg)
Die berechnete Größe umfasst die beiden Treffer nicht und unbedingt und alle Wörter dazwischen. Mit über 95% der Fälle ist somit nicht unbedingt am häufigsten anzutreffen.
Formulieren einer Wortklasse
Wortklassen werden mit dem Operator
MORPH ausgedrückt.
Zur Unterstützung der Eingabe aller möglichen Kombinationen von Wortklassen und klassenspezifischen
Merkmalen wird je nach Archiv ein
MORPH-Assistent angeboten.
Für die Verfügbarkeit, siehe die Übersichtstabelle.
Verknüpfen eines Wortes mit einer Wortklasse
Um nach einer Wortform mit zugehöriger Wortklasse suchen zu können, kann man wahlweise die gesuchte Wortform mit dem Abstands- oder dem IN-Operator mit der angegebenen Wortklassen verknüpfen:
Beispiele
Beispiel 1: Verknüpfen mit dem 0-Wortabstand
| Q1a = &Würde /w0 MORPH(NOU) |
Suchanfrage Q1a liefert alle Flexionsformen von Würde
zurück, die als Nomen annotiert sind.
Beispiel 2: Verknüpfen mit dem IN-Operator
| Q1b = &Würde #IN(FE) MORPH(NOU) |
Q1b liefert mit Hilfe des Operators IN dasselbe Resultat zurück. Dabei kann die IN-Option
'FE' oder leer sein.
Beispiel 3: Ausschließen einer Wortklasse
| Q2a = &sein #IN(%) MORPH(NOU) |
Umgekehrt, wie in diesem Beispiel mit Hilfe des IN-Operators dargestellt, läßt sich mit der ausschließenden Option % der beiden obigen Operatoren eine Wortklasse für eine gewünschte Wortform ausschließen.
| Q2b = &sein #IN(%) (MORPH(NOU) oder MORPH(VRB)) |
Q2b führt das gleiche wie Q2a für zwei Wortklassen vor.
Suchen nach einer Sequenz von Wortklassen
Mit Hilfe des Wort-, Satz und Absatzoperators können beliebige
Sequenzen von Wortklassen und Wortformen miteinander gebildet werden.
Das Formulieren von Sequenzen mit Hilfe von regulären Ausdrücken ist hingegen
nicht direkt möglich. Einzig die Wiederholungsoption
von MORPH MORPH{min:max}, siehe Beispiele 2 und 3,
ermöglicht eine kompakte Formulierung von variablen Wortklassen-Sequenzen und
darüberhinaus effizientere Antwortzeiten als mit dem Wortabstandsoperator.
Beispiele
Beispiel 1: Sequenz von aufeinanderfolgenden Wortklassen
| Q1 = MORPH(NOU) /+w1:1 MORPH(NOU) /+w1:1 MORPH(NOU) |
Q1 sucht nach einer Sequenz von drei
aufeinanderfolgenden Nomen. Es ist hierbei besonders darauf zu achten,
dass der 1-Wort-Abtand mit der Angabe +w1:1
und nicht mit +w1 ausgedrückt wird, weil in letzterem
Fall auch alle Treffer bestehend aus ein oder zwei aufeinanderfolgenden
Nomen die Suchanfrage erfüllen; Grund: MORPH(NOU) hat den Abstand /w+1 zu
sich selbst, weil /+w1 den 0-Wortabstand einschließt.
Beispiel 2: Sequenz von Wortklassen mit MORPH{min:max}
| Q2 = MORPH(NOU){3:3} |
Mit Hilfe der Wiederholungsoptionen für MORPH lassen sich Sequenzen noch einfacher ausdrücken. Diese kompakte Formulierung ist derjenigen aus Beispiel 1 vorzuziehen, da sie von COSMAS II wesentlich schneller ausgeführt wird.
Beispiel 3: Variable Sequenz von aufeinanderfolgenden Wortklassen mit MORPH{min:max}
| Q3 = MORPH(DET) /+w1:1,s0 MORPH(ADJ){1:3} /+w1:1,s0 MORPH(NOU){2:2} |
In diesem Beispiel wird nach einer Sequenz von 1 Determinanten, gefolgt von 1 bis 3 Adjektiven und gefolgt von 2 Nomen gesucht. Die variablen Sequenzen werden von MORPH mit seinen Wiederholungsoptionen schnell gefunden.
Beispiel 4: Sequenz von aufeinanderfolgenden Wortformen und -klassen
| Q4 = MORPH(VRB) /+w1:1 haben /+w1:1 (soll sollen) |
Q2 sucht nach verbalen Konstruktionen vom Typ: Verb gefolgt von haben gefolgt
von soll oder sollen.
Beispiel 5: Lose Sequenz von Wortformen und -klassen innerhalb eines Satzes
Für ein gutes Beispiel einer Sequenz von Verben in einem mit dass eingeleiteten Nebensatz, siehe folgende Suchanfragemuster.
Beispiel 6: Sequenz mit Ausschließung von Wortklassen
| Q5 = (MORPH(DET) /+w1:1,s0 MORPH(-DET -ADV -A)) /+w1:1,s0 MORPH(N) |
Gesucht wird eine Sequenz von einem Determinanten und einem Nomen, zwischen denen ein Wort steht, das weder DET noch A noch ADV sein darf.