| Seite für die Ergebnispräsentationen → Ansichten → Beispiele zur Ansicht nach Mehrwortspanne |
Beispiele zur Ansicht nach Mehrwortspanne
Anmerkung: diese Ansicht hieß früher statistische KWIC-Auswertung.
Die 3-spaltige Ergebnispräsentation, bei der jede Spalte auf- und absteigend sortiert werden kann, enthält die folgenden Daten:
- Treffergröße in Anz. Wörter
- Anzahl Treffer dieser Größe
- prozentualer Anteil dieser Größe am Gesamtergebnis
Die Treffer werden nach ihrer Größe sortiert, wobei jeder Tabelleneintrag auf das Sub-KWIC für alle Treffer der entsprechenden Größe verweist.
Beispiel 1: Auswertung eines Wortpaares
Eine KWIC-Auswertung der Suchanfrage "Papst und Tod im selben Satz" nach der Größe der Mehrwortspanne sieht wie folgt aus:
| &Papst /+s0 &Tod |
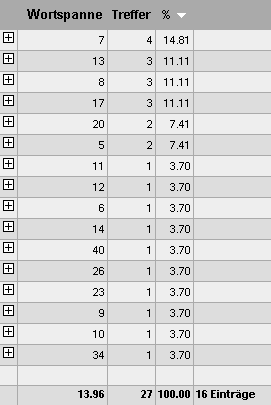
Ansicht nach Mehrwortspanne, sortiert nach dem prozentualen Anteil |
Die resultierenden 27 Treffer verteilen sich auf 16 unterschiedliche Größen bzw. Abstände zwischen den beiden Wörtern. 14,81% der Treffer haben einen Abstand von 6 Wörtern (Größe 7 - 1) und weitere 11,1% einen Abstand von 12 Wörtern (Größe 13 - 1) voneinander. Der durchschnittliche Abstand zwischen den beiden Wörtern beträgt 12,96 Wörter (Größe 13,96 - 1).
Beispiel 2: Auswertung der Satzlänge eines virtuellen Korpus
Eine KWIC-Auswertung der Satzlänge eines virtuellen Korpus nach der Größe der Mehrwortspanne sieht wie folgt aus:
| <s> |
Sätze werden mit dem Kürzel <s> abfragt. Wir haben die Auswertung im vordefinierten virtuellen Korpus lit - Belletristik/Trivialliteratur durchgeführt.
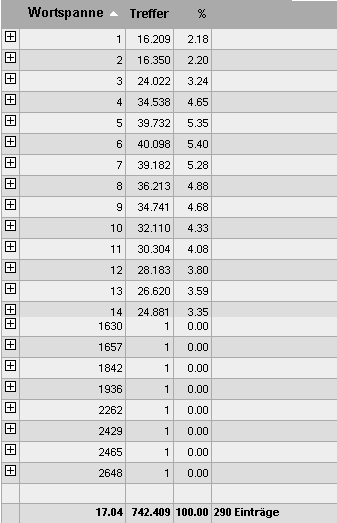
Ansicht nach der Spanne von Satzlängen (gekürzte Darstellung) |
Die Durchschnittslänge beträgt 17,04 Wörter (Größe des Satzes = Länge des Satzes). Sätze der Länge 5-7 kommen am häufigsten vor (mit je über 5%), und Sätze bestehend aus einem Wort machen 2,18% aus. Darunter sind Überschriften mit eingerechnet. Einige exotische Fälle zählen bis zu 2.648 Wörter.
Beispiel 3: Auswertung der Satzposition des ersten finiten Verbs eines Satzes
Mit der folgenden Suchanfrage läßt sich der Abstand des vordersten finiten Verbs vom Satzanfang bestimmen:
| <sa> /+s0 #BEG( MORPH(V -PCP -INF) /+s0 <se> ) |
Die Suche nach dem vordersten finiten Verb wird ähnlich wie die Suche nach dem ersten Komma eines Satzes aufgebaut. Dabei steht MORPH(V -PCP -INF), das vom MORPH-Assistenten generiert wird, für das finite Verb im CONNEXOR-Tagset (es gibt keinen direkten Suchbegriff FIN für finite Verben im CONNEXOR-Tagset).
Das gefundene Verb wird mit dem Satzanfang <sa> kombiniert. Das resultierende KWIC besteht aus den Wortpaaren Satzanfang/vorderstes finites Verb. Die "Größe" des Wortpaares ist gleichzeitig der Abstand des finiten Verbs vom Satzanfang. Größe 1 bedeutet: Verb an Position 1; Größe 2: Verb an Position 2; etc.
Für die folgende Auswertung haben wir die finiten Verben mit Hilfe des CONNEXOR-Tagsets
im Archiv TAGGED-C gesucht.
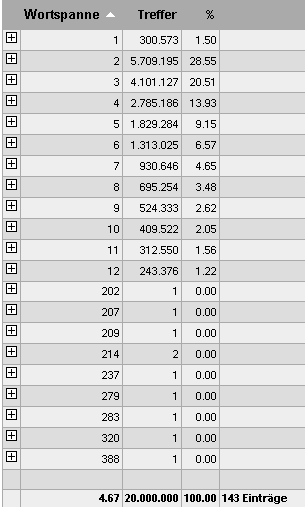
Bestimmung der Satzposition des vordersten finiten Verbs (gekürzte Darstellung) |
Die durchschnittliche Satzposition des finiten Verbs in TAGGED-C beträgt
somit 4,67.