Kookkurrenzanalyse: typische versus häufige Wortverbindungen
Im Falle von Mehrworttreffern können die Kookkurrenzanalyse einerseits und die Ergebnispräsentation nach Wort-Types andererseits teilweise ähnliche Sortierungen hervorbringen. Worauf kommt es bei den Unterschieden in der Reihenfolge der Ergebnisse an?
Die Ansicht nach Wort-Types fasst die Treffer zu gemeinsamen Wort-Types zusammen und zählt sie. In der Sortierung nach Häufigkeiten werden also die häufigsten Wortsequenzen zuerst angezeigt.
Die Kookkurrenzanalyse hingegen beurteilt die Treffer nicht nur aufgrund ihrer Häufigkeit im untersuchten Kontext, sondern auch in Bezug auf ihre Gesamthäufigkeit im Korpus. Sie ermittelt daraus die typischen Wortverbindungen und ordnet ihnen einen höheren Kookkurrenzwert zu, je typischer sie für den betrachteten Kontext im Gegensatz zum restlichen Korpus sind.
Dass die häufigsten Wortverbindungen nicht automatisch die typischsten sind, soll auf dieser Seite anhand des folgenden Beispiels aufgezeigt werden.
Nehmen wir als Beispiel die folgende Suchanfrage für das Auffinden
der Wortsequenz ein + &blau + Nomen:
| ein /+w1:1,s0 &blau /+w1:1,s0 MORPH(N) |
Die Suchoptionen sind so gesetzt, dass mit
- Groß-/Kleinschreibung = beachten und
- den Lemmatisierungsoptionen = nur Flexionsformen
Ansicht nach Wort-Types
Für die Ergebnisse wählen wir zuerst die Ansicht nach Wort-Types und lassen sie sekundär nach absteigenden Häufigkeiten sortieren. Anbei also die häufigsten Wortsequenzen bzw. -verbindungen:
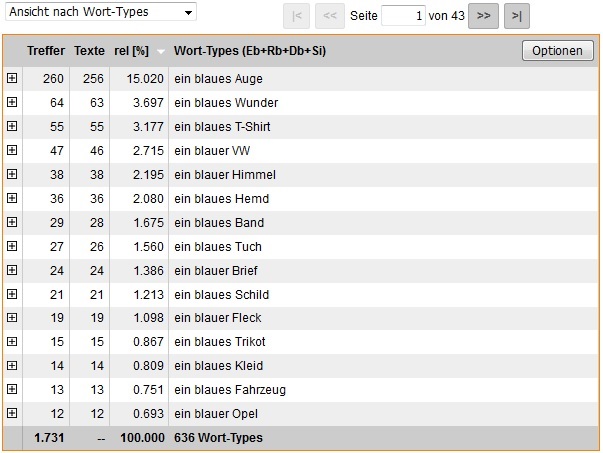 |
»ein+&blau+N«: Ansicht nach Wort-Types, sortiert nach Häufigkeiten (Seite 1) |
Kookkurrenzanalyse
Für die Kookkurrenzanalyse wählen wir :
- Kontext: 0 Wörter links bis 2 Wörter rechts
- als Kookkurrenzpartner: Treffer samt Suchwörtern zulassen
- Clusterzuordnung = mehrfach
Wir schränken bewusst den zu analysierenden Kontext auf die gefundenen Sequenzen an den Positionen 0-2 Wörter rechts ein. Damit die Treffer überhaupt als Kookkurrenzen ermittelt werden, müssen wir über eine Option die Treffer samt Suchwörtern zulassen. Für eine differenzierte Gliederung lassen wir mehrfache Clusterzuordnung zu.
Das Ergebnis sieht wie folgt aus:
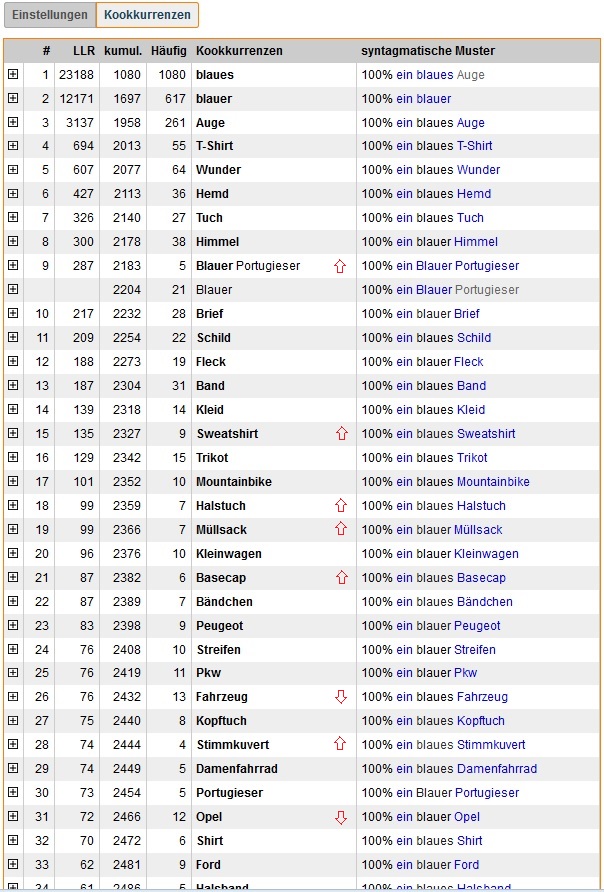 |
»ein+&blau+N«: Kookkurrenzanalyse, sortiert nach Kookkurrenzstärke (Ausschnitt) |
Vergleich
In einem ersten Vergleich beider Präsentationen fällt auf, dass Wörter wie Auge, Wunder, T-Shirt, Himmel und Hemd etc. bei beiden an erster Stelle auftreten. Ansonsten erscheinen die Wort-Types wie gewünscht streng nach ihren Häufigkeiten sortiert.
Interessant sind nun in der Liste der Kookkurrenzen diejenigen, welche durch ihre Kookkurrenzstärke deutlich höher oder tiefer eingestuft werden als man aufgrund ihrer Häufigkeit erwarten würde. Diese wurden in der obigen Liste zum diesem Zweck außerhalb von COSMAS II mit einem roten Pfeil kenntlich gemacht. Wir vergleichen jeweils ihren Rang in der Kookkurrenzliste mit dem in der Ansicht nach Wort-Types:
| Blauer Portugieser : | +40 Ränge | Mit einer Häufigkeit von 5 fällt er als Wort-Type nicht auf, in der Kook. wird die Sequenz als sehr typisch angegeben. |
| Stimmkuvert : | +39 Ränge | ist ebenfalls typischer als seine Häufigkeit vermuten lässt. |
| Halstuch : | +16 Ränge | idem |
| Müllsack : | +16 Ränge | idem |
| Opel : | -16 Ränge | ist hingegen weit weniger typisch als seine Häufigkeit vermuten lässt. |
| Fahrzeug : | -12 Ränge | idem |
Quintessenz
Die Kookkurrenzanalyse ermittelt typische Wortverbindungen, während die Ansicht nach Wort-Types, mit der Sortierung nach Häufigkeiten, die häufigsten Wortverbindungen anzeigt.